
- Community Home
- >
- Storage
- >
- Entry Storage Systems
- >
- Disk Enclosures
- >
- Re: When disk faild in VA7410, I/O throughput was ...
Categories
Company
Local Language
Forums
Discussions
Forums
- Data Protection and Retention
- Entry Storage Systems
- Legacy
- Midrange and Enterprise Storage
- Storage Networking
- HPE Nimble Storage
Discussions
Discussions
Discussions
Forums
Discussions
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
- BladeSystem Infrastructure and Application Solutions
- Appliance Servers
- Alpha Servers
- BackOffice Products
- Internet Products
- HPE 9000 and HPE e3000 Servers
- Networking
- Netservers
- Secure OS Software for Linux
- Server Management (Insight Manager 7)
- Windows Server 2003
- Operating System - Tru64 Unix
- ProLiant Deployment and Provisioning
- Linux-Based Community / Regional
- Microsoft System Center Integration
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Community
Resources
Forums
Blogs
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2007 03:55 AM
11-21-2007 03:55 AM
but
the I/O throughput was terribly reduce.
I attached more technical details.
and
I run sar -d 2 30 in normal day.
In the sar output 2 device file show busy% cose to 100%.
I'd like to know has anyone experienced similar problems before?
thanks in advance.
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2007 04:30 AM
11-21-2007 04:30 AM
Re: When disk faild in VA7410, I/O throughput was terribly reduce
I would like to add my experience with HP VA disk array's when they are rebuilding.
I recentlty had a drive fail and I had to rebuild the array after pulling the drive. The rebuild process took way longer than expected and the performance of the array during the rebuild was so bad that our production oracle database processing and filesystem dumps got messed up.
Our array used to take over 24 hours to rebuild when losing a drive. After talking to HP (and not getting any help from them) I made some changes to my setup. I bought another array and split up our storage into productiona and development. I set up the production array to be in raid 1+0 mode. This uses a huge amount of disk but the docs say it is the best performance. I also checked and tweaked some of the other parameters of the array configuration.
The array rebuild now takes 8 to 12 hours depending on I/O activity and rebuild priority. This is good news but still does not address the issue of PITIFUL performance during the rebuild process. During the rebuild process the array is essentially unusable.
So, one option is to set the array to manual rebuild. This means that I get to choose the time the rebuild runs. This is risky because if another drive fails before I rebuild the array I could end up having a really bad day.
I am now looking for an alternative to HP disk array's. It's unacceptable to have a technology this expensive that has serious problems with performance.
I would appreciate hearing about other folks experience with HP VA disk arrays. Specifically, I would be interested in hearing about solutions to the problem.
Did you find a configuration that works?
Did you replace the HP disk arrays completely, as I am now planning to do?
If you replaced your HP disk arrays, what manufacturer did you use? EMC? NetApp? StorageTek?
Any replies would be appreciated.
thanks,
kev
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2007 12:09 PM
11-21-2007 12:09 PM
Re: When disk faild in VA7410, I/O throughput was terribly reduce
I use two VA array. - va7110 + va7410.
when they are rebuilding,
VA7110 used to take over 24 hours to rebuild.
VA7410 used to take over 12 ....
and
I can not even connect to server by telnet.
Actually Our VA arrays is managed from HP.
they didn't resolve this pitifull performance during 3 years. ^^;
I am tired of this.
we are now planning to replace by EMC.
I used to many raid system - HSG80, HP EVA5000, Smart array of Proliant server.....
Nothing is wrong except VAs.
I don't really understand, why did HP sell this garbage.
but I don't want to buy New Array..
help after refer to our system config details.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2007 07:58 AM
11-28-2007 07:58 AM
Re: When disk faild in VA7410, I/O throughput was terribly reduce
Looking at the configuration details provided, it seems that CommandView SDM ver 1.09.00 is being used. I would suggest to upgrade it to ver. 1.09.02. Starting with the version 1.09.01 and firmware A140, there is a new feature called backend diagnostics and backend performance stats which are quiet useful to know what's going at the backend on the array.
Looking at the logprn result:
FRONTEND_FC_ABTS_EVENT_EH event indicates the host aborting a IO. This maybe VA didn't respond to the IO request within acceptable response time?
FRONTEND_SERVICES_EVENT_EH event, it's extend information needs to be checked. This can be checked using armdiag -W.
So I would suggest to run the diagnostics and get as much details as possible out of the running VA to know what's going on.
The HP virtual array product wasn't successful product in the market. Technically the product looked strongs but did't perform as it should be. I have seen performance problems, Auto RAID issues, many h/w failures ( backend loop issues, FC drive failures , LIP storms etc.) on this product. VA isn't a solid product as it should have been. Maybe that's why HP discontinued this product 2 years back (supporting until 2010 though) and going with MSA/EVA arrays in a big way.
I have worked on HSC,HSG,HSZ ( DEC fan) and EMA which are high performance, reliable and robust products. Nowadays MSA/EVA arrays are technically good and HP has got a good share in the storage market with these products.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2007 05:45 PM
11-28-2007 05:45 PM
SolutionI agree that a failing disk may cause an internal loop to hang.
Apropos configuration.
It looks like your setup is not optimal even with all disks working.
Have a look:
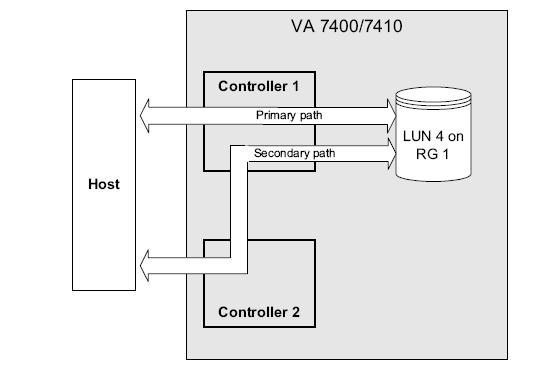
You have LUNs in Redundancy Group 1 and 2, but you access a LUN in RG 1 sometimes via the primary and sometimes via the secondary controller path. Accessing it always via the primary path will increase performance.
Example:
--- Physical volumes ---
PV Name /dev/dsk/c9t0d1
PV Name /dev/dsk/c10t0d1 Alternate Link
PV Status available
...
PV Name /dev/dsk/c10t0d2
PV Name /dev/dsk/c9t0d2 Alternate Link
This is LUN 1 and 2, but
LUN 1:
Redundancy Group:_____________________1
LUN 2:
Redundancy Group:_____________________1
You did not attach an ioscan, but I think you access LUN 2 using the secondary path which will decrease the performance.
Hope this helps!
Regards
Torsten.
__________________________________________________
There are only 10 types of people in the world -
those who understand binary, and those who don't.
__________________________________________________
No support by private messages. Please ask the forum!
If you feel this was helpful please click the KUDOS! thumb below!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2007 05:59 PM
11-28-2007 05:59 PM
Re: When disk faild in VA7410, I/O throughput was terribly reduce
Hope this helps!
Regards
Torsten.
__________________________________________________
There are only 10 types of people in the world -
those who understand binary, and those who don't.
__________________________________________________
No support by private messages. Please ask the forum!
If you feel this was helpful please click the KUDOS! thumb below!
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2007 06:04 PM
11-28-2007 06:04 PM
Re: When disk faild in VA7410, I/O throughput was terribly reduce
http://bizsupport.austin.hp.com/bc/docs/support/SupportManual/c00311965/c00311965.pdf
page 46 Product Overview
Hope this helps!
Regards
Torsten.
__________________________________________________
There are only 10 types of people in the world -
those who understand binary, and those who don't.
__________________________________________________
No support by private messages. Please ask the forum!
If you feel this was helpful please click the KUDOS! thumb below!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2007 07:23 PM
11-28-2007 07:23 PM
Re: When disk faild in VA7410, I/O throughput was terribly reduce
We solved this by disabling "Auto Rebuild" on all our VAs.
When a disk fails we wait for a period of low activity to replace, which starts balancing process for some hours then.
After that everything is back to normal.
Rgds
oliver
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-30-2007 02:43 AM
11-30-2007 02:43 AM
Re: When disk faild in VA7410, I/O throughput was terribly reduce
For HP-UX make (very) sure that a recent SCSI IO Cum. patch is installed as in older patches there's a bug that can leave the QD set to 1 for a lun (or several luns). From a host perspective it looks like a really bad performance where in fact the array is almost idle during the rebuild. Please read the text in patch PHKL_29047/29049 and look for: "SR: 8606155022 CR: JAGad24339".
The reason that this issue occurs mostly during a rebuild is because the array will send out "queue full" responses and that will cause the drive to change the queue depth from (the default) 8, to 4,2 and even 1 if they array keeps sending queue fulls. Problem with the buggy driver is that it will not go back to 8 and stay on 1 until you reboot the host. When having 10 hosts its very likely that all will have the same bad performance and hence the finger is pointed to the array.
During normal operation try to find the best setting for queue full treshold (QFT), there are several documents available how to tune it. These are configured for the host ports. Enable Prefetch should be enabled for better read performance.
Try to prevent mixing disks of different size in the same redundancy group as that may severly impact the performance.
For arrays running in autoraid modus, check out the documents regarding "magic capacity" as a wrong configuration will have a bad performance.
If there are any questions please ask, i'm convinced that the array is a good product but tuning is important!. For questions regarding a VA array please supply the output from the armdiag -I -if command.
Best regards,
Arend
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-13-2007 04:23 PM
12-13-2007 04:23 PM
Re: When disk faild in VA7410, I/O throughput was terribly reduce
I am showing up as Kathleen, but my name is Kevin. Looks like there is a problem with the login account.
Anywho, I wanted to reply again after reading some of the other replies.
Specifically, I wanted to assure Arend Lensen that the performance problem with va's during rebuild mode is not a configuration problem and cannot be fixed through tuning the array or anything else for that matter.
I have had HP support take all the information they can from my array, systems, etc, analyze it, and then make suggestions. I implemented the suggestions they made which amounted to buying more VA hardware and placing the arrays in RADI1+0 mode.
I did reduce the amount of time that a rebuild takes. But, the array is still almost completely unusable while the rebuild process is in progress. We had another episode of our production processes getting delayed so badly that there were failures.
The bottom line is that my arrays are well maintained and properly tuned. I even try to make sure that each individual drive I place in the array has the latest stable release of the firmware for that model drive! None of this matters due to the overall design of the array. There is no method of configuration or tuning that is going resolve the ridiculous degradation in performance during the rebuild process.
Here are some possible scenarios I've come up with to get around this problem:
1) I can wait until the weekend to rebuild the array during a time of relative quiescence. What if I have another drive fail during that time?
2) I can mirror everything across multiple arrays and when I need to rebuild one of them I can simply reduce the mirrors and take that array out of the equation.
3) I can scrap my 3 7400's and multiple TB's of disk and buy a better prpduct. This is an expensive solution but it's the one that is most likely to happen at this point.
It's disturbing to think that a major player would sell a product this poor knowing that there are serious problems with the technology.
If any HP support engineers reading this think they have a solution they should contact me immediately. My company is close to ditching the HP storage and the support contracts that go with them.
My email address is klister@ccah-alliance.org. I'll try to fix the account login info to my correct info but if I can't get it fixed please feel free to send me an email directly.
kev