
- Community Home
- >
- Storage
- >
- Midrange and Enterprise Storage
- >
- StoreVirtual Storage
- >
- Re: 10x increased latency and SAN errors on storev...
Categories
Company
Local Language
Forums
Discussions
Forums
- Data Protection and Retention
- Entry Storage Systems
- Legacy
- Midrange and Enterprise Storage
- Storage Networking
- HPE Nimble Storage
Discussions
Discussions
Discussions
Forums
Discussions
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
- BladeSystem Infrastructure and Application Solutions
- Appliance Servers
- Alpha Servers
- BackOffice Products
- Internet Products
- HPE 9000 and HPE e3000 Servers
- Networking
- Netservers
- Secure OS Software for Linux
- Server Management (Insight Manager 7)
- Windows Server 2003
- Operating System - Tru64 Unix
- ProLiant Deployment and Provisioning
- Linux-Based Community / Regional
- Microsoft System Center Integration
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Community
Resources
Forums
Blogs
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-11-2014 06:03 AM
09-11-2014 06:03 AM
Hello,
Since 1 week, Su August 31, we have a serious issue with our HP StorageWorks P4300 G2 Cluster.
This cluster contains 2 SANs (stor01 and stor02), each has 8 disks in RAID5. Connections are dual ISCSI 1Gb.
- 8 Volumes are configured in Network RAID 10 (2-way mirror)
- 2 Volumes are configured in Network RAID 0 (None, 1 volume on stor01 and 1 on stor02)
From august 31, we get "stor02 overload" errors in the SAN loggings. Our latency has increased 10x eversince (latency per VM from 5-15 to 50-5000). The system has 8 VMware ESX hosts connected and about 40 VM's.
To try and keep our servers running, we have limited the IOPS on the VM's. This helped keeping our database servers 'fast'.
Now sometimes, the latency is good again (like it was before august 31). I found out that this happens right after the storage reports the RAID 10 Volumes "out of sync". First I got a "stor02 overload" message, then the volumes were out of sync and latency was OK. After about 10-15 minutes, the system reporting "resynching" and latency was ultra high (>1000). When resync was complete (5 minutes), latency was again 'normal' high (>100).
Please see the attached imaged that explains. Datastore latency is the red line.
Can someone please guide me how to troubleshoot this further? I have checked IOPS on all VM's and it is very hard to find any problem. All disks are OK. I have deleted some volumes to clear space (71% free now), no advance.
on August 20, we do had Storage IO Control (VMware) disabled, but I doubt this has to do with it. Is this something we can contact HP services for? What department/number is that?
Best Regards,
Joris
Solved! Go to Solution.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-11-2014 08:34 AM - edited 09-11-2014 08:35 AM
09-11-2014 08:34 AM - edited 09-11-2014 08:35 AM
Re: 10x increased latency and SAN errors on storevirtual P4300, please help
sounds like the underlying raid group on one of your units is failing. When that happens the disk access slows down and eventually the SAN kicks that node out of the active cluster (when you see its out of sync) and then it gets put back in after the problem appears to be resolved (which it really isn't and it just appears to the node that it is because the load on the raid group is just nothing... then it all repeats as actual load is put back on the raid group). Check the raid group disks for error as its one or more disks in that group that is the problem.
Side note: network Raid 0 does NOT work like you think it does not assign on LUN to a single node like you appear to describe. Network raid0 is just like raid0 in that it is a STRIPE across BOTH nodes. When your failing node fails, you will LOSE all your NR0 LUNS. You need to get those LUNs to NR10 ASAP.
edit: if rebuild performance is hurting your SAN performance you can always turn down that rate from the default to something lower. this is done if you right click on the management group and select edit.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-12-2014 03:25 AM - edited 09-12-2014 06:03 AM
09-12-2014 03:25 AM - edited 09-12-2014 06:03 AM
Re: 10x increased latency and SAN errors on storevirtual P4300, please help
Hello,
Thank you for your reply. Now we are getting quite sure the problem is indeed in the SAN and not in IOPS overload. We are preparing to move all VM's to the RAID10 Volumes this weekend.
The process in the previously attached image is indeed repeating, also today. We are now pulling all different error logfiles and check them. The management tool does report all disks as "Status Normal".
We do see a difference in stor01 and stor02 on this:
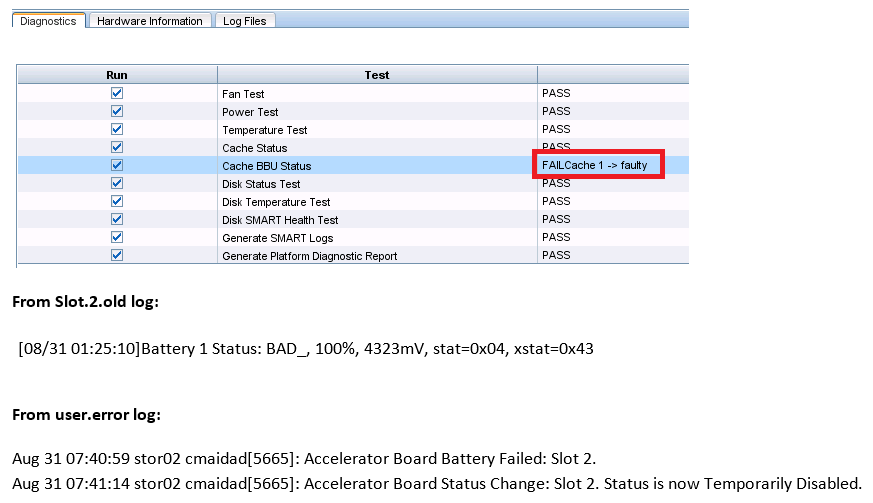
- stor02: Controller/Cache Items : Card 1: Battery Status: Faulty
See Attached image.
Could this have to do with the problem you think?
Best Regards,
Joris
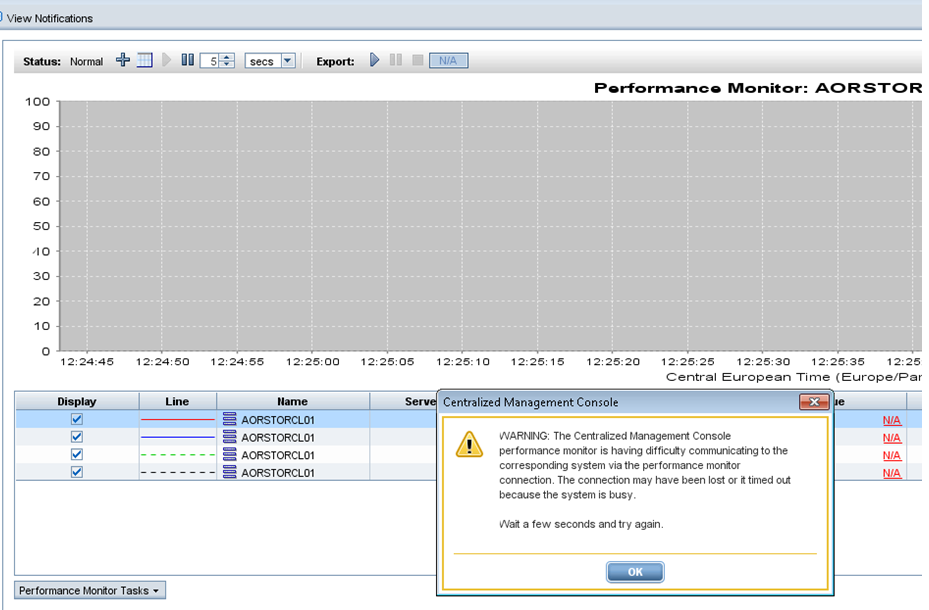
EDIT: it is also impossible to view the performance data, it sais "performance monitor is having difficulties communicating to the corresponding system". See screenshot attached.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-12-2014 06:25 AM
09-12-2014 06:25 AM
Re: 10x increased latency and SAN errors on storevirtual P4300, please help
do you not have enough capacity on the san to just edit the LUNs and set them to NR10 and let them restripe? That is what I would do and then you don't have to worry about moving the data.
If the cache backup is bad on that node it is probably also showing that its in write-through mode and not using the controller cache which means its going to be running really slow while waiting on disk latency. On top of that you might have a disk or two that is starting to fail but isn't fully failed yet and are running at higher than normal latencies at random periods. Since the SAN is only as fast as the slowest node, this is causing the SAN performance to come to a crashing halt.
I don't know if there is a way to pull the number of SMART reported bad sectors on a disk, but I bet you have at least one disk that is starting to report bad sectors.
What you should do NOW is: 1. edit the NR0 LUNs and change them to NR10. 2. Contact HP and get a replacement cache battery. 3. Contact HP and get their help to find what disk is failing on the node and replace it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-12-2014 06:42 AM
09-12-2014 06:42 AM
Re: 10x increased latency and SAN errors on storevirtual P4300, please help
That sounds like very good advise to me.
I am moving the VM's manually from 1 datastore (volume) to the other (synced) using storage vMotion or cold vmotion. I dont like to change the current volumes setup to RAID10 on the SAN because I fear that this will cause enormous latency problems.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-12-2014 08:00 AM
09-12-2014 08:00 AM
Re: 10x increased latency and SAN errors on storevirtual P4300, please help
it will probably be less than moving the data from one LUN to another. The benefit to the edit of the LUN is that you can turn down the management group bandwidth and have it run more slowly. Also in that case 1/2 your data is already on the bad node and you would only be writing the other half to it and only be reading half the data as well (per node). compair that to writing to a NR10 LUN which will write 100% of the data to both nodes you would actually end up causing more work on the Node by copying the data from the NR0 LUN to the NR10 lun instead of just converting the NR0 LUN
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-12-2014 08:34 AM
09-12-2014 08:34 AM
SolutionI fear more latency because when the system is resyncing it is similar activity (copying from 1 to the other). And resynching after fail now shows latency up to 3000 and phones coming in. If my latency goes to 3000 and does not stop before Monday, without option to "cancel" this, I will have enormous problems.
Moving a VM is latency 300 currently and takes 1 hour for 5GB (:s) but seems safer.
We have checked all the logfiles on stor02 and found:
From Slot.2.old log:
[08/31 01:25:10]Battery 1 Status: BAD_, 100%, 4323mV, stat=0x04, xstat=0x43
From user.error log:
Aug 31 07:40:59 stor02 cmaidad[5665]: Accelerator Board Battery Failed: Slot 2.
Aug 31 07:41:14 stor02 cmaidad[5665]: Accelerator Board Status Change: Slot 2. Status is now Temporarily Disabled.
This is the exact morning were all problems started.
I assume cache is disabled on stor02, and we cannot fix this without putting the SAN down.
So we are forced to get rid of the RAID0's before being able to troubleshoot this with HP I guess.
Thank a lot
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-12-2014 09:16 AM
09-12-2014 09:16 AM
Re: 10x increased latency and SAN errors on storevirtual P4300, please help
you should be able to control load on the rebuild by controlling the bandwidth assigned to it in the management group and that lets you go down to like 250kbps. Anyway, if copying is working for you then that is fine.
You should contact HP now to get the replacement parts in hand. replacing them should just require powering down the machine and then swapping the card and then powering it back up which shouldn't take more than a couple mintues and shouldn't have any data loss, so the only downtime would be on your current NR0 LUNs which are probably effectively down anyway.
That said, unless the systems are pretty heavily loaded, there has got to be a failing drive in there somewhere as you still shouldn't get 300+ms latency even if your cache is turned off. unless the que for access to your drives are sky-high.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-12-2014 12:05 PM - edited 09-12-2014 12:15 PM
09-12-2014 12:05 PM - edited 09-12-2014 12:15 PM
Re: 10x increased latency and SAN errors on storevirtual P4300, please help
I have not seen any disk errors in any of the logfiles, and there is a lot of logfiles.
There is a small exchange 2010 server on the cluster, a file server, and a quite heavy-read sql server.
Additionally there are 20 VDI Windows 7 MS office/outlook stations on it, with active antivirus.
ISCSI is only 1Gb using a shared L3 switch and disks are only 8x 7.2k 1TB RAID5 per lefhand.
In 'normal' circumstances, latency on the SQL Server could max to 30-40ms.
This system was already unsufficient before the real problems started.
So maybe without caching it can be normal to have 300ms sql peaks, and it is not a bad disk?
How could we check that? Also have it checked by HP?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-12-2014 12:56 PM
09-12-2014 12:56 PM
Re: 10x increased latency and SAN errors on storevirtual P4300, please help
What does the que say in CMC and what is your IO rate in CMC?
300 is easily possible with an overloaded system and yours wasn't fast to begin with.
I'm using 100% VSAs so i'm not sure if it gets reported through CMC, but the thing to look for is the SMART reported bad block value. If there are number of bad blocks on a drive it could indicate that its timing out on some write requests and that will make your write through cache problem worse.
I bet you are overloaded and I would see what you can shed for IO load until you get that replacement cache and then I would talk to HP about upgrading to fix your long-term IO problem.