
- Community Home
- >
- Storage
- >
- Midrange and Enterprise Storage
- >
- StoreVirtual Storage
- >
- Re: Overprovisioning when deleting snaphots
Categories
Company
Local Language
Forums
Discussions
Forums
- Data Protection and Retention
- Entry Storage Systems
- Legacy
- Midrange and Enterprise Storage
- Storage Networking
- HPE Nimble Storage
Discussions
Discussions
Discussions
Forums
Discussions
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
- BladeSystem Infrastructure and Application Solutions
- Appliance Servers
- Alpha Servers
- BackOffice Products
- Internet Products
- HPE 9000 and HPE e3000 Servers
- Networking
- Netservers
- Secure OS Software for Linux
- Server Management (Insight Manager 7)
- Windows Server 2003
- Operating System - Tru64 Unix
- ProLiant Deployment and Provisioning
- Linux-Based Community / Regional
- Microsoft System Center Integration
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Community
Resources
Forums
Blogs
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-26-2010 03:50 AM
05-26-2010 03:50 AM
First time post, so forgive me if this has already been answered - my searches couldn't find an answer.
We're currently implementing a pair of P4300 clusters to provide iSCSI storage to our fileservers. We've cloned our existing physical data to them, and are now performing testing. We're currently using thin-provisioned volumes which are provisioned to take up 8TB of the available 12TB of storage (4TB of storage in net raid 1+0). The space currently provisioned for volumes is 4TB.
We did some backup testing usiong backup exec with VSS snapshots, and did a few tests in a short period of time. One of my team then noticed that despite the above volume provisioning, the Use Summary for the cluster was reporting as over-provisioned.
Looking at the provisioning, it appears that when the VSS snapshots were released, the snapshots auto-provisioned sufficient space on the next available snapshot to allow the data on the deleted snaphot to be written down to the next snapshot.
I've done some testing, and have now established that when a snapshot is deleted, the following snapshot will provision enough space to write down the contents of the deleted snapshot. This, coupled with the fact that multiple VSS snapshots were taken in a short period, were what caused the cluster to report as over-provisioned.
Whilst we won't be doing multiple VSS snapshots per day, we were planning to run a regular snapshot schedule. However, what is now worrying me is that if the sum storage of our volumes at time of oldest snapshot took up more than 50% of the available storage, then when the oldest snapshots (containing the bulk of the data) are deleted, possbily by a snapshot schedule, then the cluster will be over-provisioned whilst the snapshots are written down prior to deletion.
Is this something I should be concerned about? Obviously we don't want write failures on our volumes every time a schedule deletes the oldest snaphots from the volume. Does the temporary over-provisioning that could occur when deleting large snapshots run any risk of this occurring?
Again, sorry if I'm asking a question with a fairly obvious answer here, and thanks in advance for your help.
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-26-2010 04:25 AM
05-26-2010 04:25 AM
Re: Overprovisioning when deleting snaphots
I believe it is artificially showing the new snapshot as additional provisioned space, even though what is really happening is the snapshot you are deleting is really just having its blocks "assigned" to a different snapshot in the chain. Since you aren't really consuming additional space I think you are pretty safe.
Now I've also setup most of my customers with Nagios monitoring, and I wrote a script that checks the "used/available" space in the cluster. It does this by doing an SNMP walk through ALL the volumes, and ALL their snapshots, and adding the total sizes together. Even when the GUI in the CMC shows over provisioning, or even I've seen negative amounts of space available (in the GUI), my Nagios monitor (graph) has never shown this, so I think it may be an anomaly with the CMC GUI display.
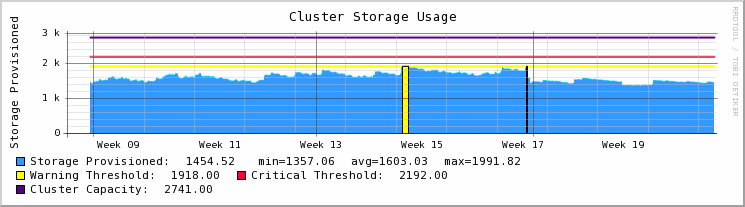{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-26-2010 09:44 AM
05-26-2010 09:44 AM
Re: Overprovisioning when deleting snaphots
Once I get snap shots going they work perfectly. I have had errors ( warnings) during setup. Today I went to setup a snap shot of a 1 tb volume. SANNIQ came up with a message that there was not enough space and the write would fail, I looked and had 1tb free. I switched it to be thin provision and the snap shot worked and didnâ t need close to the space it said it did.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-26-2010 12:40 PM
05-26-2010 12:40 PM
Re: Overprovisioning when deleting snaphots
The more changes there are between snapshots, the larger the next snapshot will be.
Looking at your numbers, do you have 12TB native (remaining space after any local RAID on the server)? And you have volumes provisioned to take up to 8TB? Is that before Network RAID is taken into account or after?
Because in your situation -
8TB (Base) + 8TB (Network RAID) + 8 TB (Snapshot) = 24TB of needed space. I know you are thin provisioned, but in this situation you will run into problems when your volumes hit 4TB of used space and perhaps sooner depending on the amount of changes happening on your volumes.
Just some thoughts, hope it helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2010 04:24 AM
05-27-2010 04:24 AM
Re: Overprovisioning when deleting snaphots
To me that means that when the full 4TB is provisioned, we would have 8TB total used of 12TB - so volumes would take up 2/3 of the available space. Given our data turnover rate almost certainly less than 10% (400GB)of total storage per week, I'd expect to comfortably be able to keep a week's worth of rolling snapshots of the volumes on the cluster.
My concern is that when releasing the oldest snapshots, which will by definition contain the data from a week ago, so potentially be taking up 8TB native, the 'thin-provisioned' snapshots above them will provision another 8tb native to take the writes....
...if this is the case then regardless of thin or full provisioning of volumes, you would NEVER be able to go over 50% use of native storage by volumes, because releasing the oldest snapshot on each volume would over-provision the cluster? Surely this can't be correct?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2010 04:39 AM
05-27-2010 04:39 AM
Re: Overprovisioning when deleting snaphots
2TB volume with 1.5tb provisioned on a 3tb cluster:
Snapshot 0=1.5TB provisioned
Snapshot 1=10GB provisioned
Volume itself = 1GB provisioned
=total 1.511TB of 3TB provisioned
Deleting snapshot 0 will cause Snapshot 1 to provision 1.51TB to accomotdate the data in snapshot 0. In this instance, despite the fact that only 1.51TB of a 3TB cluster are provisioned, deleting Snapshot0 will cause cluster to be overprovisioned as during delete:
Snapshot 0=1.5TB provisioned
Snapshot 1=1.51GB provisioned (to accept snapshot0)
Volume itself = 1GB provisioned
= total if 3.011TB of 3TB provisioned during delete.
Like I say, I hope that Teledata's response (thanks for that) is correct, and I'll contact HP to see if we can get it confirmed.
Regards,
Pete
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2010 05:55 AM
05-27-2010 05:55 AM
Re: Overprovisioning when deleting snaphots
Needless to say, I hope you update this when you hear from HP/LHN as I'm curious about exactly what you are seeing.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-27-2010 09:03 AM
05-27-2010 09:03 AM
SolutionI have to imagine that to some extend it is erroneously (or conservatively) reporting provisioned space, because, as I originally posted many times I've seen the GUI in the CMC report a negative amount of not provisioned space.
Here's some detail on the check I'm using to determine cluster space (download and examples with graph included):
http://www.tdonline.com/training/lefthand/scripts/
I've found it to work well and used it with several deployments. That said I'd love some input from others (and HP) in order to improve its accuracy. (there's also probably a much more efficient query than I've written)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-17-2010 01:54 AM
06-17-2010 01:54 AM
Re: Overprovisioning when deleting snaphots
--- begin quote from Lefthand SA ---
This is our CMC temporarily double counting both snapshots together as whilst we are showing provisioned space for both the oldest snapshot and the next snapshot up what is actually happening in the background is a small stripe of data at a time is being rolled up, checked and then deleted from the old snapshot. So you certainly do not need twice as much space on the SAN for these deletions and they are not actually causing over provisioning during this time. We do need a very small amount of working space just to roll these changes up and of course it is recommended to retain some free space on the SAN in case volumes need to grow at short notice rather than running at 100% full.
--- end quote ---
Thanks very much teledata for your script links - we're using MRTG here but I'm sure we can use the principal and the SNMP traps from your script to achieve the same effect.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-23-2010 07:50 AM
06-23-2010 07:50 AM
Re: Overprovisioning when deleting snaphots
Although I feel the check seems to be pretty accurate, it is very inefficient, it has to make a query for EVERY volume and EVERY snapshot on the cluster to add them together... however it does seem to be immune to the CMC erroneously reporting large over provisioning during snapshot rollovers....
Maybe the efficiency isn't that big of a deal, I'm not sure how much load those extra SNMP queries put on the SAN, but it is good to have the historical usage patterns graphed and archived on my Nagios server..