
- Community Home
- >
- HPE Community, Austria, Germany & Switzerland
- >
- HPE Blog, Austria, Germany & Switzerland
- >
- Oracle Desaster Recovery Lösung mit Nimble Replica...
Kategorien
Company
Local Language
Forums
Diskussionsforum
Forums
- Data Protection and Retention
- Entry Storage Systems
- Legacy
- Midrange and Enterprise Storage
- Storage Networking
- HPE Nimble Storage
Diskussionsforum
Diskussionsforum
Diskussionsforum
Forums
Diskussionsforum
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
- BladeSystem Infrastructure and Application Solutions
- Appliance Servers
- Alpha Servers
- BackOffice Products
- Internet Products
- HPE 9000 and HPE e3000 Servers
- Networking
- Netservers
- Secure OS Software for Linux
- Server Management (Insight Manager 7)
- Windows Server 2003
- Operating System - Tru64 Unix
- ProLiant Deployment and Provisioning
- Linux-Based Community / Regional
- Microsoft System Center Integration
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Gemeinschaft
Kontakt
Forums
Blogs
- RSS-Feed abonnieren
- Als neu kennzeichnen
- Als gelesen kennzeichnen
- Lesezeichen
- Abonnieren
- Drucker-Anzeigeseite
- Anstößigen Inhalt melden
Oracle Desaster Recovery Lösung mit Nimble Replication
Häufiger kommt bei Kundenterminen die Frage auf, wie man mit Nimble Storage eine Desaster Recovery Lösung für Oracle realisieren kann. Was sind die Schritte die dafür notwendig sind und braucht es eine spezielle Integration mit der Oracle Datenbank-Engine, um eine wiederanlauffähige Kopie auf der DR-Seite zu haben?
Ich habe zu diesem Zweck auf meinem Laptop mit VMware Fusion eine virtuelle Umgebung aufgebaut, die zwei Nimble Virtual Appliances und zwei Linux-VMs umfasst. Die erste Linux-VM greift über iSCSI auf die Nimble Appliance „nimble2“ (Gruppe: „grp2“) zu. Auf dieser Appliance sind drei Volumes eingerichtet, die in der Volume Collection „oracle“ zusammengefasst sind. Diese Volume Collection wird alle 5 Minuten gesnapt und dann auf die zweite Nimble Appliance „nimble1“ (Gruppe: „grp1“) repliziert. Hier soll später die zweite Linux-VM auf die Snapshots zugreifen und die Datenbank wieder starten.
In beiden Linux-VMs habe ich Oracle 11g Express Edition installiert und identisch konfiguriert. Die Datenbank-Dateien habe ich wie folgt auf die Volumes verteilt:
- oradata – Oracle Datenbereich mit Datenfiles für User-, System-, SYSAUX- und TEMP-Tablespaces,
- oradata2 – Datenbereich für einen User2-Tablespace, den ich zusätzlich zu den Standard-Tablespaces angelegt habe,
- orafra – Oracle Flash Recovery Area, in der die Online- und die archivierten Redologs liegen.
Die Oracle Binaries habe ich auf lokalen Filesystemen in beiden Linux-VMs installiert. Die Datenbankkonfiguration (Oracle „spfile“) ist in beiden VMs identisch, sodass ich später die Datenbank auf der Replika-Seite ohne Anpassung hochfahren kann.
Um ein wenig Last zu erzeugen und ständig Einträge in der Datenbank vorzunehmen, habe ich eine PL/SQL-Prozedur programmiert, die unter Verwendung einer Sequence Daten in eine Tabelle schreibt und nach jedem Eintrag die Änderung mit einem Commit festschreibt. Die Tabelle liegt im User2-Tablespace, sodass auf alle drei Volumes parallel geschrieben wird. Auch wenn im Hintergrund das Nimble-Array einen Snapshot erzeugt, arbeitet die Datenbank ganz normal weiter und nimmt ständig Änderungen in den Datenbankdateien vor. Es werden keine IOs gestoppt und die Datenbank wird auch nicht in den Hotbackup-Modus gebracht – auf diese Weise soll ein echter Crash-konsistenter Zustand gezeigt werden.
Die Volume-Konfiguration auf der „nimble2“ sieht wie folgt aus:
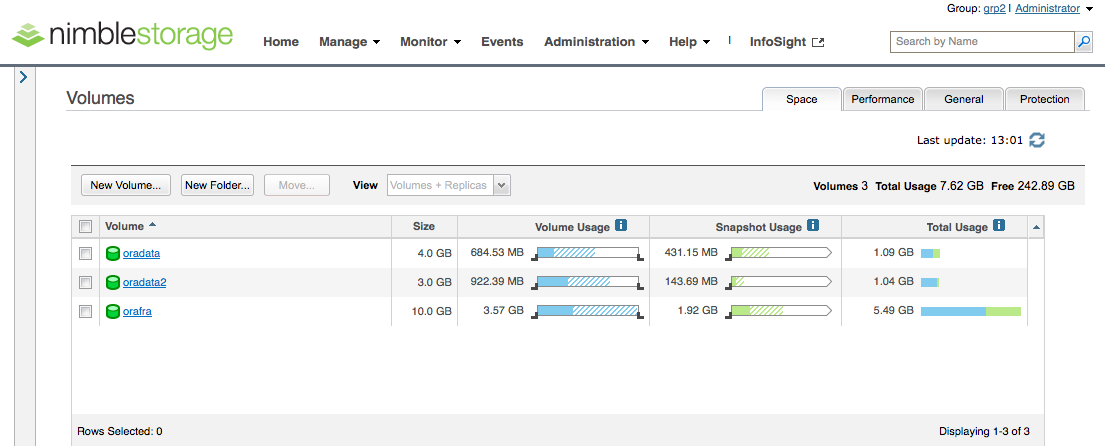
Volume Collections arbeiten wie „Consistency Groups“, d.h. das Erstellen eines Snapshots ist ein atomarer Vorgang. Für alle Volumes innerhalb einer Collection wird ein Snapshot IO-genau zum absolut identischen Zeitpunkt erzeugt. Für Applikationen, die verteilt auf mehreren Volumes laufen – insbesondere für Datenbankanwendungen – ist dies unumgänglich, um eine wiederanlauffähige Kopie zu erhalten, ohne dass man beim Erzeugen des Snapshots in die Applikation eingreifen muss. Für Oracle bedeutet dies ganz konkret, dass ein „Crash konsistenter“ Zustand vorliegt. Beim Öffnen der Datenbank überprüft der Oracle-Prozess die zugehörigen Datendateien (datafiles) auf Konsistenz, fährt bei Bedarf einzelne Transaktionen nach und schreibt sie in die betroffenen Dateien. Die Transaktionen sind in den Online-Redologs gespeichert – daher ist es wichtig, dass sowohl die Volumes mit den Datendateien als auch die Redologs in einer Volume Collection sind.
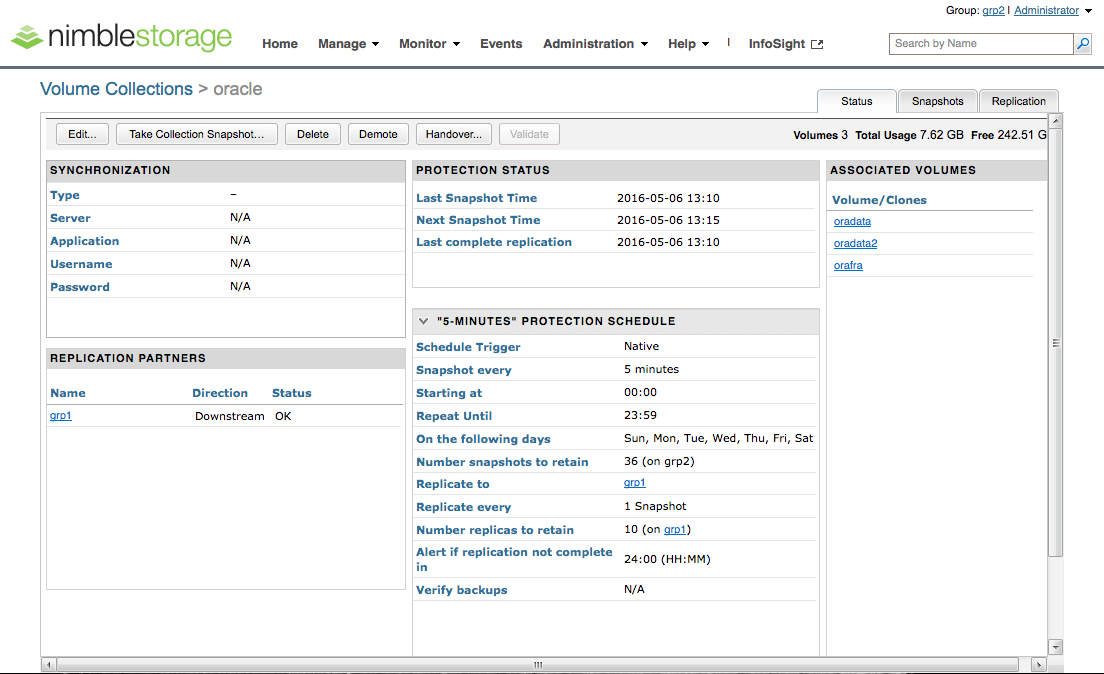
Das Setup der Volume Collection „oracle“ sieht wie folgt aus. Man sieht, dass die drei Volumes „oradata“, „oradata2“ und „orafra“ enthalten sind; es wird alle 5 Minuten ein Snapshot erzeugt, von denen 36 Stück vorgehalten werden. Jeder Snapshot wird auf den Replikationspartner „grp1“ repliziert, wo dann 10 Snapshots vorgehalten werden. Man sieht auch, dass keine „Synchronization“ mit der Applikation vollzogen wird, d.h. es werden keinerlei Aktionen gemacht, die Anwendung in einen sauberen Zustand zu bringen (im Oracle-Terminus wäre das z.B. ein „Hotbackup Mode“). Dass die Datenbank mit dem Zustand in den Snapshots trotzdem innerhalb kürzester Zeit ohne großen Aufwand geöffnet werden kann, soll der folgende Test zeigen.
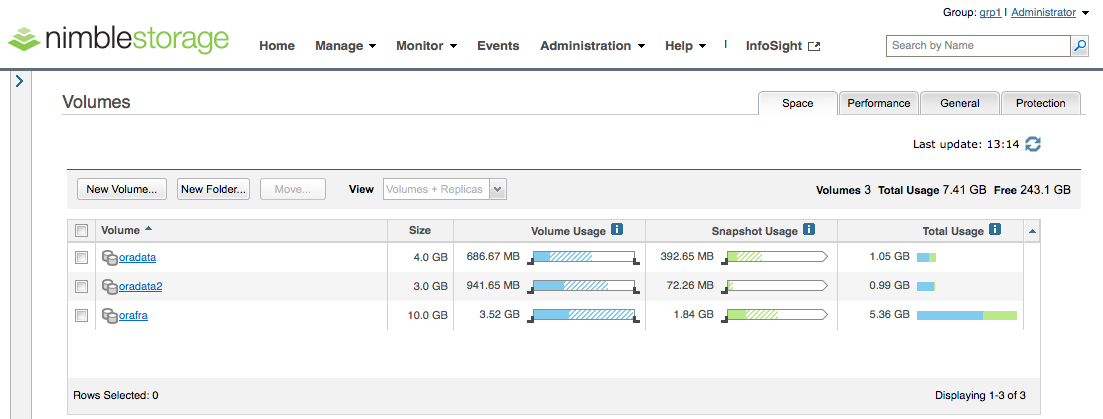
Das Anlegen der Volume Collection unter der Angabe des Replikationspartners hat das automatische Erzeugen der zugehörigen Replikas auf dem Array „nimble1“ bewirkt. An den grauen Icons mit den beiden Plattensymbolen erkennt man, dass es sich um Replikas handelt, die offline sind, d.h. sie sind für einen angeschlossenen Host nicht sichtbar:
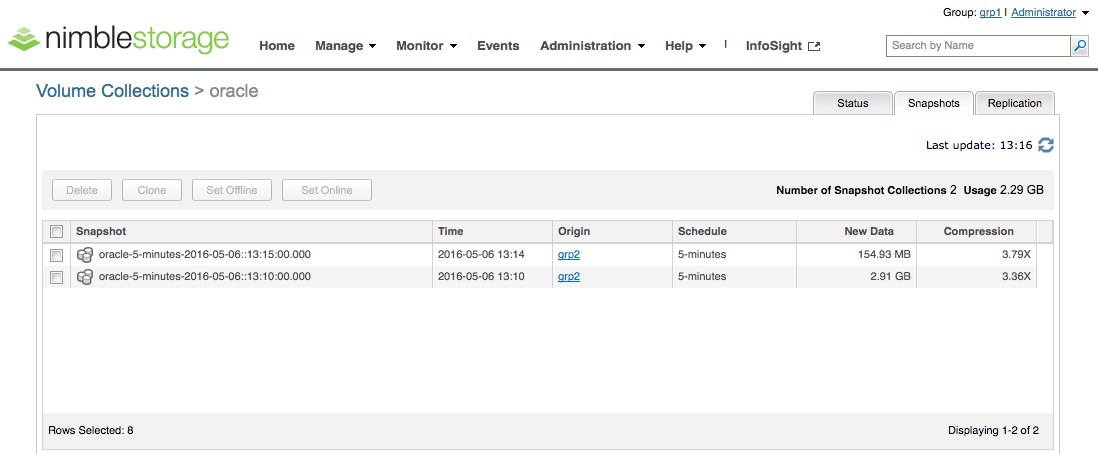
Aber nicht nur die Replikas, sondern auch die zugehörige Volumen Collection ist automatisch mit angelegt worden. Unter dem Snapshot-Tab sieht man die Snapshots, die bereits repliziert worden sind und wie viele neue Daten seitdem geschrieben wurden:
Um auf Snapshots mit einem zweiten Host zugreifen zu können, müssen zunächst „Clones“ erzeugt werden. Durch das Auswählen der Checkbox neben einem Snapshot und durch Klicken auf „Clone“ starte ich den Prozess. Zunächst werde ich danach gefragt, wie die Clones für die einzelnen Quell-Volumes heißen sollen:
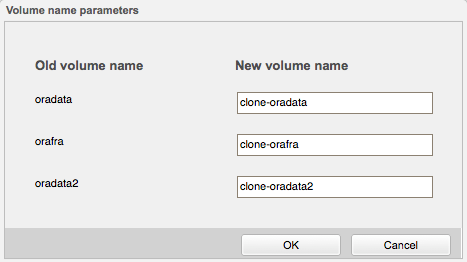
Anschließend erscheinen die Clones wie normale Volumes in der Übersicht. Sie sind zunächst offline, sodass ich sie online schalten muss, und danach kann ich die Zuweisung an die zweite Linux-VM vornehmen.
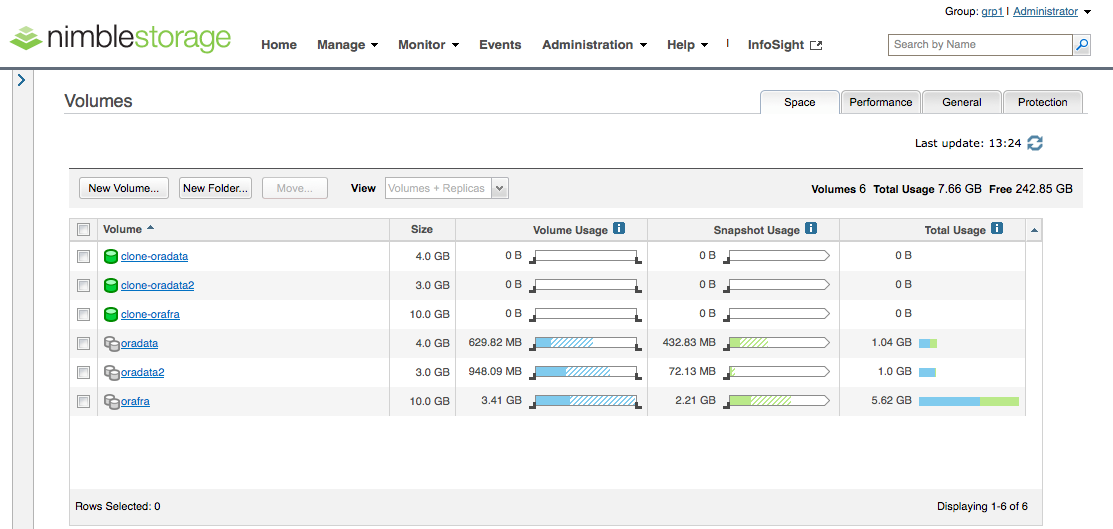
In der Linux-VM sehe ich nun über iSCSI die drei neuen Disks und logge mich auf den Targets ein:
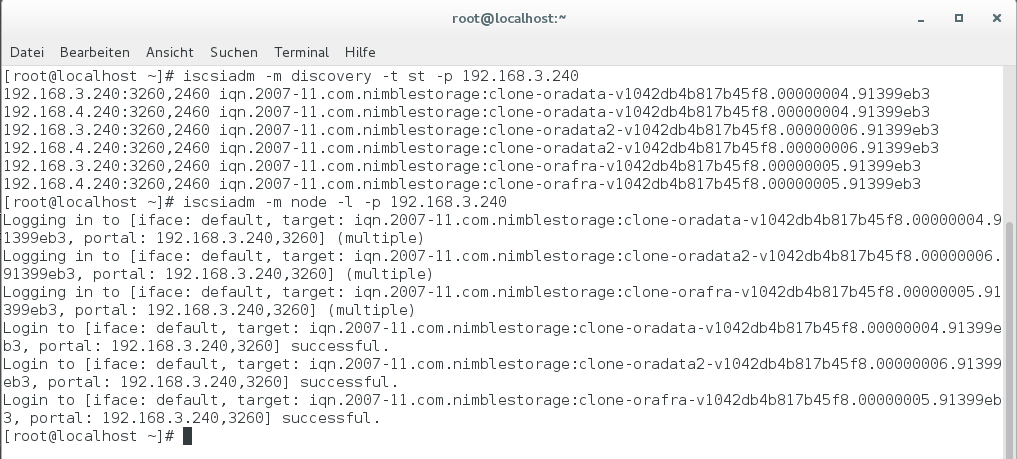
Der Multipath-Treiber erkennt die beiden Pfade je Disk und stellt mir die Pseudo-Devices dm-0 bis dm-2 zur Verfügung, die ich anschließend ganz normal mounten kann. Ich verwende dazu die gleichen Mount-Points wie auf der ersten VM, damit die Pfade auf die Oracle-Files identisch sind und ich keine Änderung in der Datenbank-Konfiguration vornehmen muss.
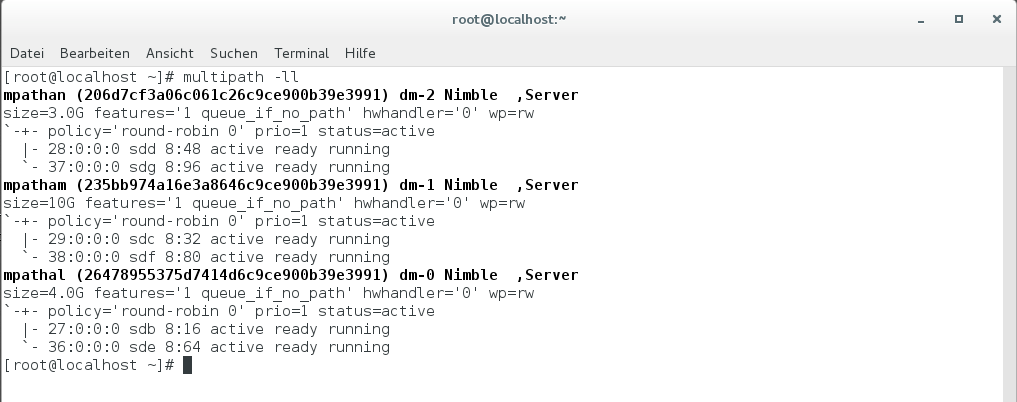
Mit dem df-Befehl sehe ich die neuen Filesysteme und die Auslastung:
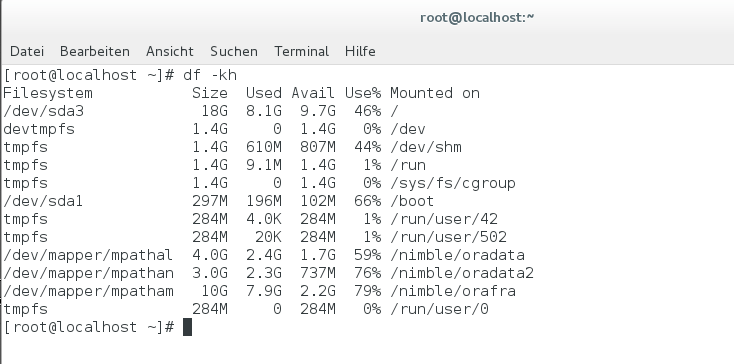
Nun kann ich die Datenbank ganz normal hochfahren. In der zweiten Linux-VM verbinde ich mich dazu als User oracle mit der Oracle-Instanz:
[oracle@localhost ~]# sqlplus / as sysdba
Anschließend kann ich die Datenbank mit dem Befehl startup hochfahren.
Sobald die Datenbank vollständig geöffnet ist, schaue ich mir den Inhalt des Alert-Files an. Hier sieht man, dass die Datenbank um 13:37:04 gemountet wird. Um 13:37:09 wird sie geöffnet und die Crash Recovery beginnt, die bis 13:37:25 – also 16 Sekunden lang – dauert. In Summe fährt die Datenbank also in weniger als einer halben Minute hoch.
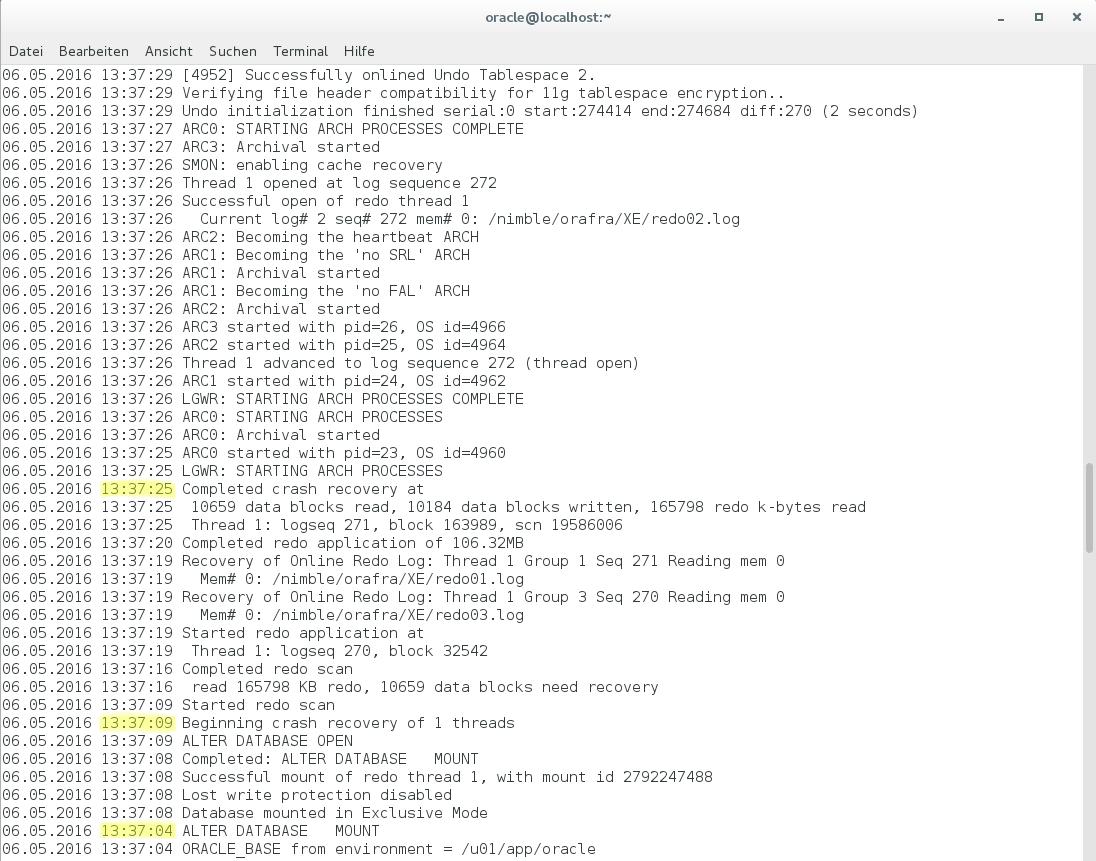
Ich kann jetzt dieselbe PL/SQL-Prozedur wie in der ersten VM nutzen, um Last zu generieren und Tabelleneinträge zu erzeugen. Die Daten, die dabei geschrieben werden, sind in der Nimble-GUI als „Volume Usage“ der Clones zu erkennen:
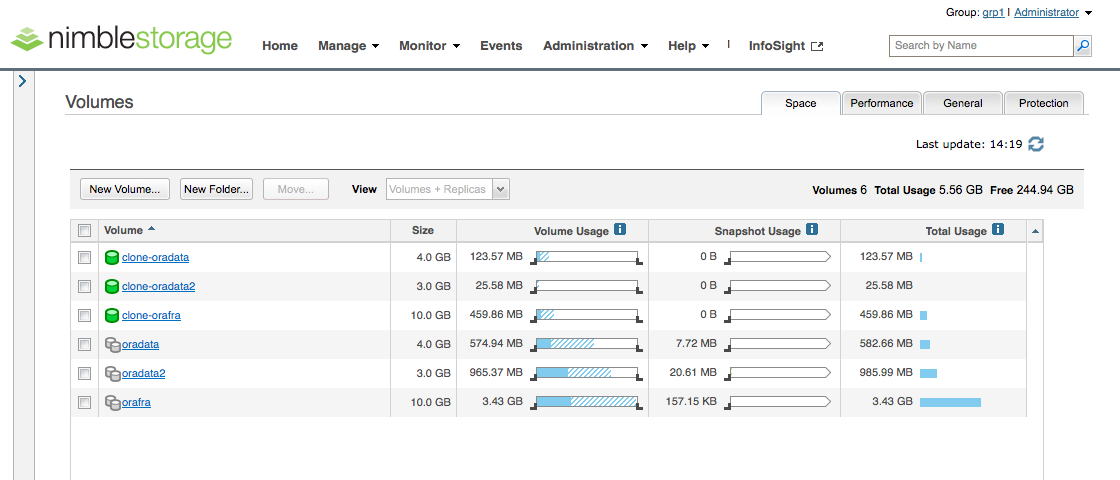
Bei dieser Gelegenheit möchte ich noch kurz ein Blick auf die Kompressionsraten werfen. Wie wir weiter oben in dem ersten Screenshot des Arrays „nimble2“ sehen, liegt die physikalische Nutzung der einzelnen Volumes bei:
- oradata -> 684MB
- oradata2 -> 922MB
- orafra -> 3,57GB
Die Nutzung aus Sicht der Linux-VM stellt sich wie folgt dar:
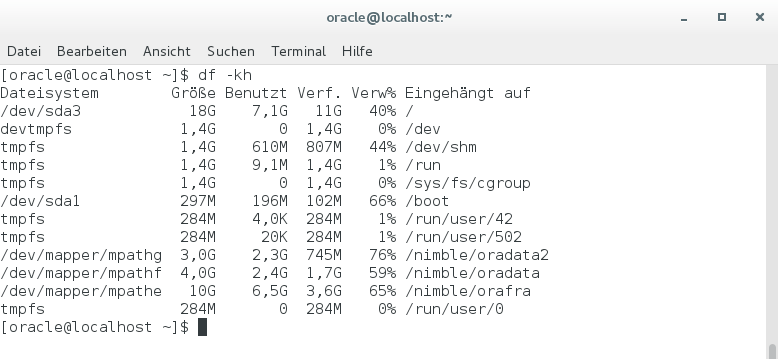
Aus Oracle-Sicht sind allerdings einige Blöcke ungenutzt – mit Hilfe einer kleinen Query kann man sich die freien Kapazitäten in den einzelnen Tablespaces anzeigen lassen:
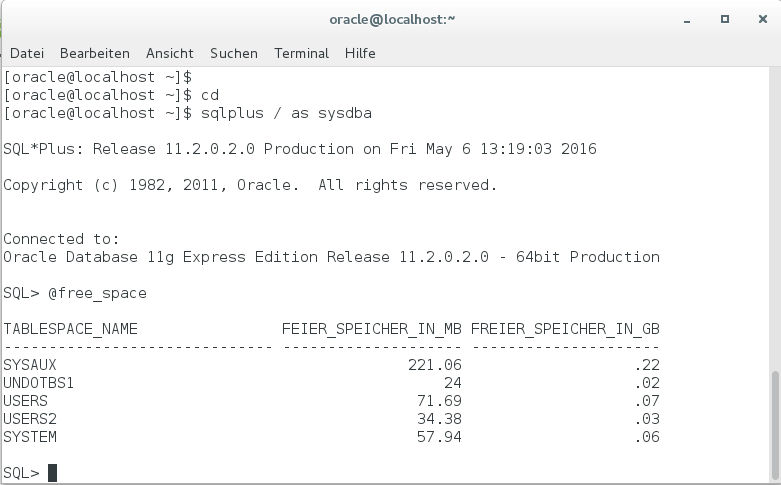
Wenn man diese freien Kapazitäten von den Linux-Belegungen abzieht und dann mit der physikalischen Ausnutzung auf dem Nimble-Array vergleicht, ergeben sich folgende echte Kompressionsraten:
|
Volume (Tablespaces) |
Belegung Linux – freie Oracle-Blöcke |
Physikalische Belegung Nimble |
Kompressions- rate |
|
oradata (SYSAUX, UNDO, USERS, SYSTEM) |
2,4GB – (0,22+0,02+0,07+0,06)GB = 2,03GB |
684MB |
~2,9:1 |
|
oradata2 (USERS2) |
2,3GB – 0,03GB = 2,27GB |
922MB |
~2,4:1 |
Es handelt sich hierbei natürlich nur um eine sehr kleine Testumgebung und die Ergebnisse sind sicherlich nicht repräsentativ für große Produktivumgebungen. Sie zeigen aber eine gute Tendenz, und ich persönlich denke, dass man guten Gewissens mit einer Kompressionsrate von 2:1 für Oracle-Datenbank auf einem Nimble-Array ausgehen kann. Dieser Wert deckt sich auch mit den Ergebnissen, die wir in unserem Predictive-Analytics Tool InfoSight sehen – und die Werte dort basieren auf nahezu allen produktiven Nimble-Systemen weltweit.
jmaue133
- Zurück zum Blog
- Neuerer Artikel
- Älterer Artikel
- Martin Fryba auf: HPE verpflichtet Lieferanten auf wissenschaftlich ...
- ThoRah auf: Initiales Setup eines Nimble Arrays
- UO auf: Höchstleistung aus dem Rechenzentrum
- gregor58 auf: VVols - Ganz einfach mit Nimble
