
- Community Home
- >
- Storage
- >
- HPE Nimble Storage
- >
- Application Integration
- >
- Number of VMs per datastore and alerting
Categories
Company
Local Language
Forums
Discussions
Forums
- Data Protection and Retention
- Entry Storage Systems
- Legacy
- Midrange and Enterprise Storage
- Storage Networking
- HPE Nimble Storage
Discussions
Discussions
Discussions
Forums
Discussions
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
- BladeSystem Infrastructure and Application Solutions
- Appliance Servers
- Alpha Servers
- BackOffice Products
- Internet Products
- HPE 9000 and HPE e3000 Servers
- Networking
- Netservers
- Secure OS Software for Linux
- Server Management (Insight Manager 7)
- Windows Server 2003
- Operating System - Tru64 Unix
- ProLiant Deployment and Provisioning
- Linux-Based Community / Regional
- Microsoft System Center Integration
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Community
Resources
Forums
Blogs
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-23-2015 10:10 AM
02-23-2015 10:10 AM
Number of VMs per datastore and alerting
I noticed the following posting by Nick recently
https://connect.nimblestorage.com/thread/1887
with the link to Jason Boche's blog post:
VAAI and the Unlimited VMs per Datastore Urban Myth » boche.net – VMware vEvangelist
and the recommendation
"10 HIGH IO VMs, 15 AVERAGE IO VMs or 20 LOW IO VMs."
Other than monitoring VM latency is there any proactive way of monitoring for datastores beginning to breach thresholds where performance will be impacted? I've read various blog posts on using esxtop but most of those are for diagnosing the root cause once you have a performance issue.
Overall it would be good to be able to alert on any LUN resource constraints for the VMs before they actually experiences issues. I was also thinking some of those "LOW IO" VMs could become high IO VMs and cause a performance impact for all the VMs on that LUN.
Thanks
Martin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-25-2015 12:02 PM
02-25-2015 12:02 PM
Re: Number of VMs per datastore and alerting
I've heard good things about products from VM Turbo and Solarwinds to provide this sort of monitoring and alerting within a vSphere environment. Perhaps Storage DRS could also be used to facilitate these sorts of concerns around latency/disk queues on a datastore level?
twitter: @nick_dyer_
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-27-2015 04:48 AM
02-27-2015 04:48 AM
Re: Number of VMs per datastore and alerting
Thanks Nick, we currently use Solarwinds so I'll have a look in there.
Doesn't using SDRS result in all of the Thin Provisioned LUNS eventually ending up thick until you run UNMAP?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-19-2015 11:13 AM
03-19-2015 11:13 AM
Re: Number of VMs per datastore and alerting
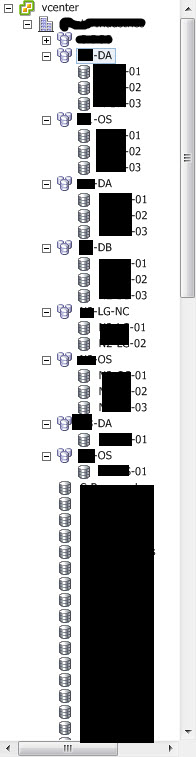
We've taken on a hybrid plan for our datastores, a mix between the unlimited VMs per DS and specific DS for high IO VMs.
What we did was leverage our VMware Ent+ license level with datastore clusters and then broke them out to OS, DA, DB, LG-NC clusters of several DS each. OS for C drive, OS partitions and so on. DA for data partitions, D drives, etc. DB for database and high IO drives. LG-NC for logs and non-cache drives such as backups and so on. We just allow for storage DRS to handle IO or latency issues as they arise. We are alerted and we can take action if the issue lingers for a prolonged period. Short anomalies aren't much of a concern.
If there are specific machines that require unique settings we can create those datastores and apply whatever we need there.
-ajw