- Community Home
- >
- Storage
- >
- HPE Nimble Storage
- >
- Array Performance and Data Protection
- >
- How to improve low sequential read performance for...
Categories
Company
Local Language
Forums
Discussions
- Integrity Servers
- Server Clustering
- HPE NonStop Compute
- HPE Apollo Systems
- High Performance Computing
Knowledge Base
Forums
- Data Protection and Retention
- Entry Storage Systems
- Legacy
- Midrange and Enterprise Storage
- Storage Networking
- HPE Nimble Storage
Discussions
Knowledge Base
Forums
Discussions
- Cloud Mentoring and Education
- Software - General
- HPE OneView
- HPE Ezmeral Software platform
- HPE OpsRamp Software
Knowledge Base
Discussions
Forums
Discussions
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Discussion Boards
Community
Resources
Forums
Blogs
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-14-2016 03:15 PM
12-14-2016 03:15 PM
I was running some performance tests on a small CS/1000 with a well tuned Centos 7.2 system running under VMware, using an external iSCSI LUN from the Nimble CS/1000.
I was very pleased with write performance of both small and large files (Nimble's forte), but was disappointed with the moderate levels of sequential read performance for large, multi-gigabyte files.
For example, when writing a 10 GiB file to a tuned XFS file system, I am achieving over 550 MB/sec rates ... using uncompressable data. When I read the same file back (after flushing the Linux file cache buffers), I achieve only 145 to 180 MB/sec.
I'm using Linux block-layer settings on the "sd" entries of max_io_kb of 1024, read_ahead_kb of 4096, nr_requests of 128, with a queue depth of 64. The same settings are on the multipath pseudo device.
Monitoring the performance as the test is running, I can confirm that 1 MB reads are being done at the iSCSI layer. The system uses a dual 10GbE NICs, with dual subnets into the two 10GbE ports on the Nimble storage.
I understand that Nimble CASL architecture identifies large sequential reads and performs them directly from the disks. However, with an 18+3 CASL layout with a total of 21 disks, I would expect a higher sequential read performance than 9-10 MB/sec per physical disk.
The Nimble volume is using a 4kb Nimble block size, with a 4kb XFS page size, with proper alignment.
What large file sequential read performance should be expected on a CS/1000 ?
Thanks for your help.
Dave B.
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2016 04:18 AM
12-15-2016 04:18 AM
Re: How to improve low sequential read performance for large files?
Dave,
Using tools such as IOMeter/IOStat with 256K block sizes, 32 outstanding I/Os and multiple CPU threads with a minimum of 4 iSCSI paths on dual 10Gb NICs we have observed the CS1000 to perform at around 1000MB/sec and writes being around 700MB/sec as an absolute maximum. Of course this is in a perfect environment so your mileage may vary.
Sounds like something isn't configured correctly somewhere in the stack. Might be worth a call into Support (and your local Nimble SE) to see if they can assist.
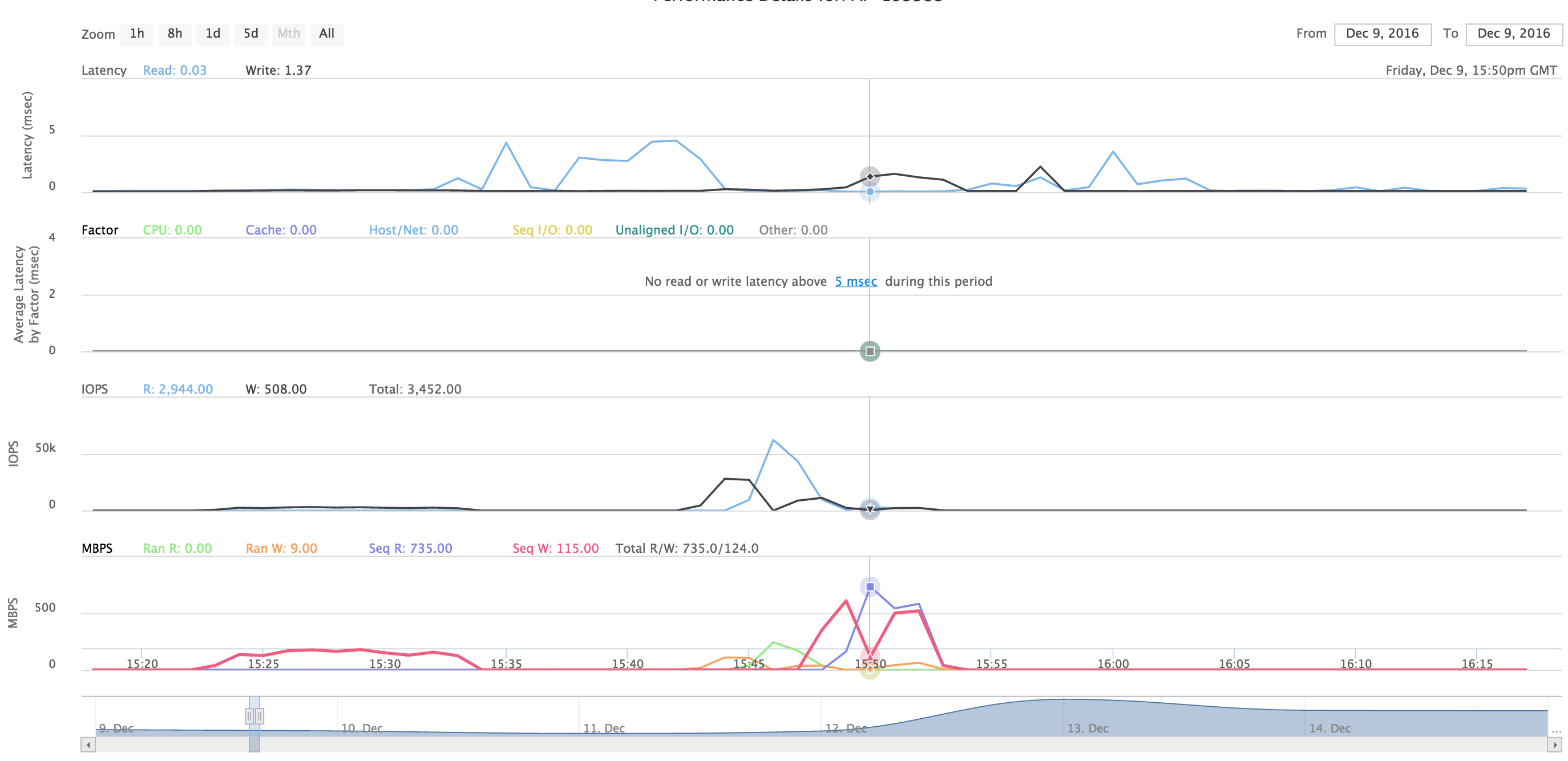
To give you an example I performed a similar test with a CS1000 with 8GB FC using IOMeter recently - and was able to stress it at 735MB/sec without any tuning whatsoever. I'm pretty sure I could get it higher if I spent the time tweaking various knobs. Mixed 50/50 read/write sequential performance was 585MB/sec read, 522MB/sec write for a total of 1107MB/sec.
twitter: @nick_dyer_
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-15-2016 07:38 AM
12-15-2016 07:38 AM
Re: How to improve low sequential read performance for large files?
Hi Nick,
Thank you for the information. I read it with caution, because the comparisons are not really equivalent. But, I really appreciate that you took the effort to reply.
The comparison is really apples and oranges. Your suggestion to call Nimble support is likely the best guidance.
Iometer is a useful tool, but for many of us, running a zillion threads to different files with a 50/50 read/write mix is not the real world, especially for bulk "administrative" -kind of tasks.
But as a comparison point, with it is a useful marker.
Also, please note, that not all storage vendors have architectures that handle "large files" well, and these vendors are very successful in in the non-large-file market.
There are a broad class of storage vendors that operate in the 12-15 MiB/sec per physical spindle tier of performance, so my 9-10 MB/sec is not that bad for a simple test. With compressible data, that number could double. There are also other storage vendors that operate at a ~30 MiB/sec per spindle performance tier.
Storage vendors that target the HPC and "big data" market typically operate at a ~60 MiB/sec per spindle performance tier, and the top-end for 7200 RPM disk performance (multi-stream sequential) is around 75-90 MiB/sec per spindle. One of the gating factors to these higher levels of per-spindle performance is the IO size per disk. To sustain multi-stream sequential performance at 60 MiB/sec/spindle, you have to ensure a minimum effective IO size of at least 1 Mbyte to each disk. The fact that many storage vendor's architectures were limited to using smaller IO sizes was part of the justification to Hadoop-like software-defined architectures that ensure 1-4 MiB or larger IO sizes per spindle. I have worked for HPC-class storage vendors, and also for HPC-class customers doing their own storage integration, so I understand the underlying issues.
As a new Nimble user with significant storage experience, I am trying to understand how well the Nimble handles "large files" ... which admittedly is outside its primary market. The challenge with "large files" is that it effectively negates the benefits of the SSDs for the "data". The SSDs are still very important for write caching, metadata, and non-large files.
The significant differences in your described iometer test:
1) I am interested in a SINGLE large (10+ Gbyte) file, sequential access, read performance. Given the CASL architecture, this kind of workload would bypass the SSDs and be serviced directly from the disks. This is also uni-directional performance, which stresses the unidirectional performance of the connections (other than a small amount of IO acknowledgements going the other way. The only available IO optimizations are likely compression, read-ahead, how the IO is spread across multiple disks and the effective read IO size per spindle, the tightness and CPU efficiency of the IO stack, and how efficient the math algorithms are that are used to generate checksums, parity, and the like. Nimble has a valuable feature of explicitly handling silent data corruption, which ultimately requires a computation and comparison of a checksum across the data ... for every read.
The large 10 Gbyte file size, accessed in a single pass also minimizes the potential impact of staging the data into the SSD tier or the RAM cache. Ultimately, you can't go any faster than the disks ... and the effectiveness of the fan-out parallelism to read multiple disks in parallel. This one-to-many parallel expansion is a function of the Nimble firmware and the host read-ahead settings. I was using the recommended Linux setting of a 4MB read ahead with 1 MB max_sectors_kb IO size.
2) iSCSI over Ethernet/TCP. iSCSI has significantly more "compute" overhead than fibre channel with a good controller. Properly configured, a 4 MB FC IO generates one host interrupt. iSCSI requires several hundred at best. This allows a host IO stack to process higher throughput levels with less CPU overhead. But the iSCSI infrastructure can be significantly less expensive. From personal experience, I can run at 98% of quad-channel FC on the host ... and do it into a single multipath IO stream (assuming the storage system(s) can keep up). Getting dual 10GbE NICs to operate above ~ 900 Gbytes/sec (which is ~75%) is increasingly difficult, especially at low thread counts.
BTW, I was testing an best-case scenario. I verified that the 10 GiB file was physically contiguous in the file system, and it was written all at once on a relatively idle system.
If I bypass the XFS file system, and do a sequential read of the LVM logical volume, I get similar performance. I can also read at the LVM physical volume level, the multipath device level, and the block device "sd{xx}" level and performance is similar, so there is minimal additional overhead being introduced on this large-file sequential read.
By going through the levels, however, I did discover at the LVM logical-volume level, the logical volume appears as a pseudo-disk, with disk-like attributes, such as "max_sectors_kb", read_ahead_kb, queue depth, number of requests, and others, but NOT the IO scheduler type. Nimble documentation suggests settings for these class of attributes at the block-layer and multi-path layer, but not the logical-volume layer. Nimble's recommended max_sectors_kb of 1024 for a 1MB IO size existed at the multipath layer, and the block layer, but the logical volume layer had the default value of 512 kb. So the 1 MB IO was being decomposed to 2x512kb in the logical volume layer, and then coalesced back at the multipath layer. Even so, the throughput was effectively the same, there was a bit more host CPU expended.
I will call Nimble support, but from my testing, it appears that the Nimble CS/1000 uses physical disk management architecture that yields the typical ~15 MB/sec per spindle (as many other vendors do), which can be increased by the compression factor. The underlying physics would be an effective per-disk read IO size of 256kb, or 4 back-to-back 64kb reads before incurring a rotational latency penalty.
Again, Nick, thank you for taking the time to contribute the information.
The iometer multithreaded read/write results are interesting, but still illustrate a maximum ~500 MB/sec read performance of compressible data, which could be 250 GB/sec of uncompressible data. My single-threaded large file read test (with read ahead) of uncompressible data is approaching 200 MB/sec ... which is not that far off. 200-250 MB/sec for 21 disks is in the classic 10-15 MB/sec design class.
Dave B
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2016 02:55 PM
12-16-2016 02:55 PM
Re: How to improve low sequential read performance for large files?
David, out of curiosity, what is the application that needs to do a single threaded read of a large file? Can the read not be multithreaded instead?
Single threaded sequential is subject to things like queuing issues that can slow things down. Applications like DBs that need to do a massive table scan (which looks like sequential reads) still do this in a multithreaded fashion.
But maybe your app is single-threaded.
Thx
D
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2016 04:07 PM
12-16-2016 04:07 PM
Re: How to improve low sequential read performance for large files?
Hi Dimitris,
Thank you for chiming in.
The primary purpose of my question about sequential read rate (with read-ahead), is that I have found it a good indication of he sequential and "large IO" capabilities of the storage system, and to help identify if there are mis-configurations in the IO stack. Sequential IO of a large file is very easy to parallel-ize with system read ahead threads, without any fancy programming. It also is often quite typical of administrative tasks working with large files.
So please let me clarify ... this is single-threaded at the application level, but potentially deeply threaded with kernel read-ahead threads. Nimble's standard recommendation is to set the Linux block-layer "read_ahead_kb" setting to 4 MiB, with a maximum IO size (max_sectors_kb) set to 1 MiB, as an example. In this case, when the Linux detected a sequential pattern, 4 x 1 MiB reads would be launched by kernel threads. There are read-ahead and IO size attributes at the block, multipath pseudo-device, and LVM logical volume layers of the IO stack, independent of what other read ahead might be done at the file system layer. XFS, the file system I was using does not itself have any additional read-ahead functionality, but other file systems that can run on Linux can.
In reality, when an simple input-process-output style application reads a large file sequentially at the application level using normal IO in a file system such as XFS, very quickly, a sequential access pattern is detected by Linux and read ahead is initiated by asynchronous kernel threads, while the original read request's data is returned to the application. Ideally, the read-ahead kernel threads can read data from the storage system faster than the application can consume it. In my simple test program, there is no processing of the data, so the application is basically measuring how fast the read-ahead can work in conjunction with the storage's capabilities.
As an aside, when I was working in storage systems that were designed focusing on "big data" applications and multi-petabyte file systems, a single threaded read application as described ran at 3,150 MB/sec on a system with 4x8gbit FC controllers. To sustain that read rate, a 6 x 8 MB = 48 MB or larger read-ahead was occurring, with each parallel 8MB IO running at about 600-650 MB/sec each, with the IO being multiplexed across the quad FC controllers using a well-tuned Linux dm-multipath.
Another example of a popular "single threaded" application is "rsync" . Rsync is used to copy and synchronize changes across disparate source and targets. It handles one file at a time, perhaps overlapping some input with output, and depends upon the source's read-ahead capability, and the targets write-behind capability to enhance its performance. When rsync hits a large file, the file is handled serially.
A second major factor for large file performance is how the file is striped across the disks, and how large the IO size given to a single disk, before moving to the next disk in the stripe. With 7200 RPM disks as the basis, the storage marketplace falls into 4 major tiers. General purpose storage typically yield ~ 12-15 MiB/sec per physical spindle, based on a 256kb or 4 x 64kb max stripe depth. The second tier is at 25-30 MiB/sec per spindle with 512kb or 4x128 kb stripe depths. The third tier, which is the low-end of the "big data" and HPC-focused storage is at ~ 60 Mib /sec per spindle, with 1 Mib or 4x256kb stripe depth. The fourth tier is at 75-80 MiB/sec per spindle with 2 MiB or 4 x 512 kb stripe depth. These last two tiers are often associated with Hadoop, IBM Spectum storage (GPFS), Lustre, Quantum StorNext, ZFS, Panasas, Infinidat, and others. These IO sequential IO rates are for disk-based IO, not SSDs. How these systems ensure and maintain 1MiB and larger IO per spindle (without breaking it up) is part of their "secret sauce", with several different approaches in the marketplace.
I don't know the details of the internal architecture of Nimble. The CASL architecture has significant benefits and ease of use that these other large-file-focused systems do not have. If Nimble's core disk topology is oriented toward 256 kb stripe depths, as most general purpose storage is, then there is a 12-15 MiB/sec/spindle ceiling, assuming no other bottlenecking issues, and my 8-12 MiB per spindle read rates are "normal", and something is not grossly mis-configured on the host or network side. If the Nimble core disk topology is oriented to the 1Mib or greater stripe depth, then this would be the 60+ MiB/sec per spindle performance tier, and my 8-12 MiB/sec per spindle rates would be indicative of some gross mis-configuration.
Back to Dimitri's question, there are many applications that deal with large, multi-gb flat files, with a simple single-threaded approach ... at the application-level. These applications depend on the kernel and/or file systems read-ahead and write-behind threads to parallel-ized the IO stream for higher levels of throughput. Being able to use simple off-the-shelf, input-process-output style applications and still get excellent performance is a benefit. Most of the standard Linux tools that handle "bulk" data operations of moving, copying, loading, restoring are often serial at the application level, and are examples of these class of applications.
Dave B.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-13-2017 11:58 AM
01-13-2017 11:58 AM
Re: How to improve low sequential read performance for large files?
Dave, look up Little's Law.
For a single threaded workload, network latency does affect throughput quite a bit. For example, if testing with FC, network latency is lower, and throughput even for a single thread can be faster. With iSCSI, latency might be naturally higher, and that could affect throughput (regardless of array architecture - this is a pipe thing).
You can calculate this on your own and derive theoretical max bandwidth for a single threaded workload regardless of array. Just calculate your host to array latency really accurately so your math is correct.
What's the array latency when you're doing your single threaded test?
Also, what's the array performance policy and block size? If you have workloads that do large sequential reads you may want to set one up with 32K (on the array side) if you have a volume that will consistently expect high sequential IO with large block sizes (say for an HPC workload). If it's truly mixed, then leave it at whatever the application really is (general purpose or a specific one like a DB profile).
You can always look at InfoSight Labs to see, per volume, what your true I/O heatmap is block-size-wise.
In general though, our systems are optimized for multi-host, concurrent multi-workload access, with auto-QoS, auto headroom optimization, etc etc (check my blog at recoverymonkey.org). The sequential-optimized systems you mention do really poorly on general-purpose stuff (and have next to zero data services, fancy checksums and no triple parity RAID), but do well on single threaded workloads, especially if network latency is really low (which is why many HPC systems don't even use a network but rather use direct SAS and in the future NVMe connections to the disks - removing network latency is important for those apps).
The question is, what do you need to do primarily?
You could also go the FC route if you want to lower network latency.
Thx
D
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-03-2017 09:42 AM
02-03-2017 09:42 AM
Re: How to improve low sequential read performance for large files?
We've had some back and forth over email, but here's one thing I forgot to mention and which might help throughput.
Increase the iSCSI minimum session count to 4. Should take effect within 90 sec.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-06-2017 12:56 PM
04-06-2017 12:56 PM
SolutionHello all,
It has been a while. I've been busy at work and did not have time to post my results.
This is a long post. Please take the time to read it. I believe it will be worthwhile.
It also discusses some things that Nimble support staff are often too polite to tell or infer to their customers.
In a way, a lot of this is RTFM ... and don't ignore the instructions.
The above answer relating to NCM is NOT the correct answer, because we are NOT using NCM.
I want to thank all that help contribute both in the forum and offline through email.
The frank and useful discussions from Dimitris and others were useful in two primary ways.
First, Nimble support staff confirmed a level of performance that was expected and had been demonstrated in the lab. This confirmed where I though the large sequential IO "ceiling" should be for the storage I was using if nothing "else" was in the way.
The second thing, to paraphrase, was to "check the plumbing". Nimble can not run any faster than the pipes it is given, and the level of congestion and locking that might be happening in intermediate layers.
Nimble's various "best practice" recommendations are very good and better than many of their competitors, but many such recommendations steer the administrator to avoiding sources of congestion and locking and improving efficiency. The recommendation often don't explain their rationale or offer troubleshooting details. We all have to remember that Nimble is a storage company, not a systems integrator or IO stack developer.
Nimble has the difficult tradeoff of trying to provide concise recommendations (and auto-adapting tuning) that are short enough to be read and not so overly verbose that they are too long and not read.
Check the plumbing.
We've all head the old adage about not to "assume" something, but we all also are tempted to make some level of assumption ... that something was done properly ... without validating it. Trust is good, but sometimes, it needs to be validated ... especially if the results seem contrarian.
If these ideal conditions exist, then the performance level should be "xxxx". Well, if this statement is correct, and you are not achieving "xxx" ... then the pre-conditions are not true.
Are you certain that the system-level HARDWARE settings for "high performance" are properly set? Since many of us run virtualized, it may be difficult to say.. But there are ESXi CLI commands, ilo commands, and vendor-specific BIOS-probing commands that will allow you to confirm that you are running in "high performance mode" as defined by the system vendor.
To make a long story short ... in several of the systems I was running on, this basic premise was NOT true, In some cases, it was a 33% penalty here, a 10% penalty there, a 40% penalty somewhere else, but they ultimately add up. No one had ever validated that the HARDWARE was set up properly.
Here are a few of the high points.
1) "Performance mode" vs. "Power saving mode". Modern CPUs are so sophisticated now that they can actually trigger micro-sleep during the inter-packet gap of a 10GbE packet stream. If this micro-sleep gets triggered, it will be 50+ microseconds to wake up, which is equivalent to several packet times.With this happening, you will never drive a 10GbE link at 10 Gbits.
The various power-saving modes can also slow down the CPU clock, in some cases to below 10% of the nominal speed. And it takes tens of microseconds to resume full speed. And at 10GbE speeds, a packet could be as short as 1/15'th of a microsecond! So it can easily take hundreds of packet times to resume full speed.
The difficulty of this performance vs power savings setting is that it could be happening in the system BIOS, the vritualization hypervisor, the VM profile, or the guest OS itself. Just because the virtual guest is running in (virtual) "performance mode", it does not mean that the VM profile, hypervisor, and BIOS are ensuring that it is enabled.
The second difficulty is that in many cases, as long as you are "busy", you might be able to stay in "performance mode". But when you become less than 100% busy, even for a moment, you are slowed. Being slow when you are doing nothing is ok, but the transition to full speed is NOT instantaneous. Now you have a thousand packet time delay before you get a chance to acknowledge that 10GbE packet.
2) Hyperthreading slows serialized code paths by about 33%, and much of the network stack is serialized between two endpoints. A hyper-thread only runs at about 75% of full speed, but you can run twice as many of them ... if you have that sustained level of multi-threaded-ness. On a 16-core server, you would need to SUSTAIN 21 hyper-threads of activity before you processed more work than 16 cores working at full speed. If you can't sustain this level of multi-threaded-ness, you are running 33% slower. For Linux administrators, your sustained Linux "load factor" would need to be greater than 1.3 times the number of cores ... or greater than 21 on a 16 core system. My 16 core systems seldom see load factors that high .... and 5-12 are typical. Note: some heavily over-subscribed virtualized environments do have very high levels of sustained multi-threaded-ness and run better with hyperthreading enabled. A web server handling thousands of connections is another example.
3) High speed controllers in slow-speed physical slots. Most high-speed 10GbE NICs and 8+ Gbit fibre channel controllers need 8-lanes of PCIe 2.x bandwidth to operate at full speed. Faster interfaces are even more demanding. Unfortunately ... not all physical slots that have 8-lane MECHANICAL connectors have 8-lane ELECTRICAL connectors. Most servers don't have enough aggregate bandwidth to allow every slot to be 8-lane, and not every interface needs that speed. So some slots only have 4-lane or 1-lane electrical connectors.
Often, the "fast" slots are the lower-numbered slots, and the "slow" slots are the higher numbered slots. If your server started with lower-speed devices (like 4 x 1 gbit NICs), and later upgraded to 10GbE, there is a strong chance that the new upgrade high-speed controller is in a higher-numbered slow-speed slot. Many administrators would avoid moving the existing controllers (to free a high-speed slot) because the controller "naming" often changes when you move it to a different slot. So VMware vmnic3 all of a sudden becomes vmnic9, and your existing VM NIC resource assignments are incorrect.
What's this mean? You can't get 2-port 10GbE performance from a 2-port controller if it is physically located in a slow-speed slot. Then you add network virtualization overhead, and you are slower still. In my instance, EVERY server I audited with 3 or more PCIe controllers had at least one high speed controller in a slow speed slot. Since the first two slots were usually high-speed, if you had 2 or less controllers it did not matter if you happened to put a slow-speed device in a high-speed slot.
4) Disk partition alignment, lack-of-contiguousness, shallow read aheads, allowing for 1 MB of IO read ahead per physical disk. To make a long story short, Nimble is a member of the high-performance tier of storage vendors that can sustain 60+ MiB/sec sequential throughput to a cost effective 7200 RPM disk under ideal conditions. This is enabled through the CASL architecture which allows variable block sizes and 1MB IOs to individual disks. Not all storage architectures allow this. There is a prominent 3-letter storage vendor whose internal architecture limits them to 256kb IOs, and limits their performance to 15-20 MiB/sec per physical disk under ideal conditions. For those vendors, they are forced to use more expensive 10K and 15K RPM disks or SSDs to achieve 60 MiB/sec/disk (best case). There is also a middle tier of vendors limited to 512kb IO per disk, with an ideal 30-35 MiB/sec/disk limit.
Well ... if you are using a 4 MB read ahead setting, and architecture tries to exploit 1 MB IOs to disk, you might be only touching 4 disks with that read head ... for 4 x 60+ MiB/sec/disk performance target = 240 MiB/sec nominal. Nimble compression may help, but also may reduce the number of disks involved. So ... if you really want to stream sequential performance, you probably want 8+ disk's worth of read ahead or more than 8 MiB. Will it make a difference? It depends on if there are other congestion and locking issues in the way. That is why (in my opinion), that Nimble suggests a 4 MiB read ahead ... and then recommends using an 8-way striped volume in Linux, each volume with multiple paths ... yielding perhaps as much as 32 MB of read-ahead. It may be very difficult to get to get more than 4-8 megabyte's worth of read-ahead against a single volume in a virtualized environment with the added congestion of the virtualized network stack. On a "real" 64-bit Linux system with quality controllers in a high-speed slot, with proper disk partition alignment, contiguous extents of tens of megabytes, 16MB read ahead (and its resulting performance) is easily achievable.
Proper disk alignment and disk-contiguousness are important. Mis-alignment is a sleeper because Nimble does such a good job at re-alignment that single stream performance is often not that bad ... but you consume more storage resources than necessary to achieve that performance level. As you add additional activity, the Nimble storage becomes more-busy, more-quickly, reducing the overall aggregate workload that can be sustained. Re-aligning IO is basically "unconstructive" work that steals resources from other IO.
You often see these issues from "legacy" systems .... older environments that were not alignment-aware, and were using older file system technology that did not yield large contiguous IOs .. that were moved to the virtual environment "as is", with no change in their disk structure. Many organizations, my own included, have many such systems. The old DOS and Linux disk partition format started the first partition at location 63 on the disk and often created disk structures with modulo 63 or modulo 255 alignment. That is not very "friendly" to the 4kb/8kb/16kb, and similar "binary" alignment preferred by contemporary hardware and software. Contemporary disk formats are aligned typically at 2048 blocks (1 MiB) today. ... so take the outage, create a properly aligned disk format, and copy the data over. (easier said than done :-)
5) If you are running older hardware/firmware ... check for already known bugs, solutions and workarounds. We had an system with a 4 year old, lower-grade Ethernet switch that was seeing a catastrophic read performance drop to ~10 MB/sec on a 1 gbit line. This value oriented switch had very shallow buffers (much less than the 512kb per port recommended by Nimble), and enabled a QOS-related feature by default. This unused QOS feature reduced the buffer inventory 4-fold, causing buffer-related packet-drops. This was a known issue, with a known solution on the vendor's forum ... upgrade the firmware, disable the feature. Performance improved from 10 MiB/sec to 104 MiB/sec on a 1 gbit connection .... no other changes. An interesting side note. This switch was working "fine" for years. We recently started using some previously unused ports, and the aggregate activity level crossed some threshold where the buffer starvation issue was exposed. Some of these "new" ports were used by systems using Nimble storage, and "tainted" the Nimble experience.
6) Get access to a non-virtualized environment, or create a "live-CD" Linux bootable flash drive with some performance tools so you can help isolate what the non-virtualized hardware can do. The Linux live-CD would contain "lspci" and "dmidecode" which can tell you exactly what controller is running in which slot, and the negotiated bus speeds for each slot. Some simple port-to-port IO tests can be illuminating. I found it straightforward to get 780+ MiB/sec read, 1040+ MiB/sec write for large files on OLD host hardware without virtualization .... and struggled to get 300-500 MiB/sec using a virtual server on much newer host hardware.
7) All the other performance tuning stuff, including settings recommended by Nimble. Yes, these are important, but if you have gross inefficiencies in the low-level platform, tuning the higher levels will not have the impact expected. In fact, with inefficient lower levels, you can draw incorrect conclusions about the value and usefulness of higher-level tuning and configuration.
Check the plumbing. :-)
Dave B
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-06-2017 02:14 PM
04-06-2017 02:14 PM
Re: How to improve low sequential read performance for large files?
Great post. Very informative.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-06-2017 06:58 PM
04-06-2017 06:58 PM
Re: How to improve low sequential read performance for large files?
One more point I almost forgot.
RSYNC (and beware of SELinux and "bulk" operations)
Do you tense up when I mention “rsync”?
I think rsync has gotten a bad rap, especially since RHEL/CentOS defaulted to enabling SELinux on install by default for recent versions.... and NOT fully configuring the SELinux security context(s) for the packages included in the distribution.
Why? SELinux, if enabled (even in “permissible”, non-enforcing mode) still goes through all security context-based checking, and if you actually did not pro-actively set up SELinux (and the security contexts for each and every installed package and user role) .. then almost every file access causes some form of exception, which is prepared for logging, so you can determine what to fix. The final logging to disk may be disabled by output filtering, but SElinux is still going through all the work.
Any product that often runs as root to access files across multiple groups of users (like rsync, tar, cpio, and other “backup” and “replication” tools) need to be pro-actively configured into SELinux …. Effectively you need to give rsync permission to access files it does not own, and even more permissions to access extended attributes, and even more to transform those attributes. Normal installation procedures do not create all these security contexts. Ideally, IFF these security contexts were properly created and assigned to the parent folders of directory trees … the security context would be inherited as subordinate files were created, and all would be good.
Otherwise … every file, and every attribute that rsync tries to touch generates an internal exception that gets summarized and readied for logging, and then usually thrown away.
So ….. take a small file system with 736K files consuming about 516 GB. Not a large volume.
Set up two systems with equivalent file systems. Set the systems up to use the rsync server protocol so there is no “remote” file access across the network (each system is talking to its local iSCSI volume), with the pipelined rsync protocol used between systems to identify the delta. Assume files with same name, timestamp and length are the same (ie, don’t do a checksum compare).
Now … run for a day … and change a total of ~5300 files, out of 736,000 files … a total of about 35 GB of the 516 GB total.
How long does the optimized rsync take with SELinux enabled in “permissive” mode on source and destination (the default) ?
Lets see.....
- Scan 732k - 736K file names, time stamps and lengths on 2 different systems in parallel
- Identify 5300 to 11000 files of 35 to 106 GB in total size that are different and transfer them
How long? What might be the difference?
Filename scan rates over 1,000 per second, right?
WRONG!
Take a look at this summary:
| Warning: Beware of SELinux and "bulk" file operations | |||||
| SELinux | |||||
| Enabled | Disabled | ||||
| Incremental rsync (optimized) | Permissive | no attributes | |||
| Total files: | 732,517 | 736,868 | |||
| Total GiB: | 478.890 | 480.218 | GiB | ||
| Changed files: | 11,157 | 5,363 | |||
| Changed GiB | 105.880 | 34.793 | GiB | ||
| Incremental rsync time (HH:MM:SS) | 11:17:49 | 0:11:32 | |||
| (Seconds) | 40,669 | 692 | |||
| Difference | |||||
| Scanned files per second: | 18.01 | 1,064.84 | 59.12 | -fold | |
| MiB transferred per second: | 2.67 | 51.49 | MiB/s | 19.31 | -fold |
| Average transferred file size (MiB) | 9.72 | 6.64 | MiB/s | ||
| Note: | |||||
| To remove all the SELinix extended attributes took ~ 3.5 hours | |||||
| itself via a shell script. | |||||
With SELinux, fully disabled, the rsync scanned the files 59-times faster resulting in the changed files being transferred about 19-times faster. 11 hours vs 11 minutes. Quite a difference.
I know Nimble is fast …. But if the Nimble storage was running with SELinux enabled, and the lesser competition was running without SELinux enabled, it would not be a fair fight. It would be very difficult to overcome a 20+ fold difference in performance.
Beware of SELinux

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-07-2017 12:07 PM
04-07-2017 12:07 PM
Re: How to improve low sequential read performance for large files?
Clarification on the SELinux results in the previous post.
The left column is run #1 with SELinux enabled. The file counts and sizes vary because this was on a live system.
Right column is run #1, with SELinux disabled, one day later. Files counts and sizes are a bit different, and there happen to be fewer files modified.
The number of files changed and the size of the changed files that were transferred have NOTHING to do with SELinix. It is just variation in the workloads from day to day.
All SELinux effects is the efficiency and resources needed to perform the file scans and transfer the changed files.
Dave B
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-20-2017 01:59 PM
07-20-2017 01:59 PM
Re: How to improve low sequential read performance for large files?
An additional update.
Check the plumbing ... part2
Fingerprint of marginal cable discovered.
Another long post, but worth the read if you are having erratic performance.
Administrators .... pay attention to VMware ESXi's or VCenter's alarms related to excessive latency to Nimble volumes.
If you are an administrator of the Windows or Linux guests VMs .... talk to your VMWare administrators. There may be IO latency problems that VMware is correctly identifying ... that are being masked from the VM guests.
We were getting alerts about excessive latency ... greater than 2 to 4 seconds ... reported by VMware, but they were intermittent. With further analysis across multiple VMware servers, we identified that all these alerts (from different servers) involved the same Nimble controller storage port.
Over a period of several months, and then weeks ... the frequency of alerts was increasing to eventually dozens per day ... when the system using the Nimble would "freeze" for tens of seconds. In some cases, the guest VM or even the hypervisor itself would timeout and crash.
We performed all the normal things ... updated all the system firmware, rebuilt the hypervisor software using the latest patched ISO media, gaining all driver and software fixes .... and still the problem persisted.
Frustration. Nimble reputation was being tainted (but it was not a Nimble problem).
Finally ... we realized .... per Nimble best-practices, all our server systems are dual-pathed, and also dual-pathed to the Nimble storage. Why not just "fail" the problem path in the VMware hypervisor. We did, ... and voila, performance was restored to normal levels. This clearly reinforced the value of dual-pathing all the way to the storage.
The only shared component was the 10GbE path from the Ethernet switch to the Nimble storage, which happened to be a switch-vendor-supplied, lower-cost, one-piece copper cable with embedded SFPs.
We swapped the cable, re-enabled the path in the hypervisor, and all was well again. Hooray! We then failed the original "good" cable to force all the traffic through the new cable ... and all was well. We then re-enabled the original good path.
Check the plumbing.... Intermittently bad cable, with errors masked to guest VMs. Only Hypervisor can detect and report excessive latency.
We don't know exactly why VMware waited excessively long times, possibly retrying the IO on the same (bad) path, rather than switching to the good path. The challenge was that the cable was failing intermittently, and enough packets were getting through (slowly) to prevent VMware from marking the path bad. Perhaps some of the VMware-level iSCSI and/or multipath time constants need to be lowered when you are working with a dual-pathed connection to allow for a "crisper" automatic disabling of a "sick" path.
Nimble Support .... any suggestions for crisper handling of sick paths?
We did some postmortem work, and found that the Nimble controller port ... was reporting NO errors. The Ethernet switch port of the bad cable had only 5 errors over several hours ... but ALL the other ports on ALL the other switches had zero errors. So the port with the intermittent cable was very different (5 errors) than the good ports, but it was not a "smoking gun". But it was different.
We were not surprised that the Ethernet switch port of the bad cable was not experiencing dropped packets. This is the behavior of hardware flow control, which was enabled per Nimble and switch vendor recommendations.
We also found that the Ethernet switch buffer usage for the port with the bad cable was also not high ... the buffers were not backing up (on the egress port to the bad cable).
However, we later discovered that there were ingress buffer backups on the other Ethernet switch ports associated with the VMware servers. It like when there is an accident on a highway exit ramp. There is no backup on the exit ramp itself, but the backup overflows onto the traffic lanes feeding the exit ramp. We were originally looking at the exit ramp (and finding nothing).
The servers were trying to write to the port of the bad cable ... and could not. It caused an eventual backup on the VMware server Ethernet ports ... because they could not do any more writing. Fortunately for us, (and per Nimble best practices), the VMware ports were used solely for iSCSI traffic, so only iSCSI traffic was impacted. This impact affected all iSCSI traffic through that server-to-Ethernet-switch path ... not just the Nimble traffic. But non-iSCSI traffic was using other paths ... and you still could login to the servers.
We were fortunately able to correlate the iSCSI TCP transmit backup to statistics visible in the ESXi host.
Thus we had a “fingerprint” of the bad behavior, and could also confirm that the bad behavior had been removed.
A document is attached that explains the ESXi command that can be used.
The command is run from the esxi ssh session as root:
esxcli network ip connection list | egrep “Proto|:3260”
The third column in the output is the labeled "Send Q", and is the bytes waiting to be sent. It should normally be zero or a few thousand bytes or less. In our case, with the marginal cable the value was over 250,000 bytes and stayed at those levels for tens of seconds. This was not an intermittent burst of traffic.
Here is an example of the bad behavior:
esxcli network ip connection list
Proto Recv Q Send Q Local Address Foreign Address State World ID CC Algo World Name
tcp 0 0 127.0.0.1:8307 127.0.0.1:29529 ESTABLISHED 36139 newreno hostd-worker
tcp 0 890 127.0.0.1:29529 127.0.0.1:8307 ESTABLISHED 34248 newreno xxxxxxxxxxxxx
tcp 0 0 127.0.0.1:443 127.0.0.1:29965 ESTABLISHED 680261 newreno xxxxxxxxxxxxx
tcp 0 865 127.0.0.1:29965 127.0.0.1:443 ESTABLISHED 1149555 newreno python
tcp 0 255952 10.0.1.61:38818 10.0.1.2:3260 ESTABLISHED 1148128 newreno xxxxxxxxxxxxx
(MARGINAL CABLE)
Example of normal behavior:
esxcli network ip connection list | egrep "Proto|:3260"
Proto Recv Q Send Q Local Address Foreign Address State World ID CC Algo World Name
tcp 0 0 10.0.1.68:19040 10.0.1.2:3260 ESTABLISHED 33564 newreno vmkiscsid
tcp 0 0 10.0.1.68:55904 10.0.1.2:3260 ESTABLISHED 33564 newreno vmkiscsid
tcp 0 0 10.0.1.68:28167 10.0.1.2:3260 ESTABLISHED 32806 newreno idle0
tcp 0 0 10.0.0.168:30850 10.0.0.2:3260 ESTABLISHED 32806 newreno idle0
tcp 0 0 10.0.0.168:31725 10.0.0.2:3260 ESTABLISHED 33564 newreno vmkiscsid
tcp 0 0 10.0.0.168:48374 10.0.0.2:3260 ESTABLISHED 32806 newreno idle0
tcp 0 0 10.0.0.168:62504 10.0.0.150:3260 ESTABLISHED 32806 newreno idle0
tcp 0 0 10.0.1.68:51109 10.0.1.151:3260 ESTABLISHED 32806 newreno idle0
tcp 0 0 10.0.0.168:43242 10.0.0.18:3260 ESTABLISHED 33564 newreno vmkiscsid
Check the plumbing ... with a fingerprint of a marginal cable.
Dave B.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-20-2017 02:03 PM